…という類<たぐい>の質問に答えるのはちょっと面倒なんですけど、とりあえず1つだけ具体例を挙げておきましょう。テンプレート処理が、もろにモナドになっている、ってハナシ。今回はテキスト処理について説明。次回(いつになるかまったく不明)はXML処理の予定。
テキスト処理だけでも長ーい説明(最長記録かも)なのだけど、分割すると“勢い”がなくなるから一挙掲載。読むときはユックリ・ジックリ読んでくださいね。プログラミング課題も、実際にコーディングしないまでも、「こうやればいいな」という方針くらいは考えてください。
※印刷のときはサイドバーが消えます。
内容:
- ネストしたテキスト
- テンプレート処理
- ブロック、文字列、名前
- フラット・テキストとテンプレート・テキスト
- 多段階のテンプレート処理
- 素材を整理しよう
- モナドに向かって突っ走れ!!
- バッチリ、モナドだぜぇ
- 残りは脱兎のごとく
- 最後に言っておきたいこと
[修正/非修正の予定と履歴]
変なところや不十分なところをいくつか発見。
- 「素材を整理しよう」の等式群に間違いがあるかも。→間違ってなかった。が、補足が必要だから追加した。
- 「バッチリ、モナドだぜぇ」の最後の説明が変。→直した。
- クリーネ・スター級数の記述は混乱を与えるだけのような気もする。→まだ、そのまま。
- オーバーロード版processは、実用上は便利そうだが、理屈の上では不要だった。が、これは変更しないと思う。
- プログラミング課題8を追加。
- プログラミング課題5内のプログラミング課題3への参照は間違いで、プログラミング課題2でした。
- ext((ext(con2))・con1) = ext(con1)・ext(con2) は間違い。ext((ext(con2))・con1) = ext(con2)・ext(con1) でした。
ネストしたテキスト
'{'と'}'を特別な文字(特殊文字、メタ文字、区切り文字)として予約して、左右の括弧'{'、'}'がちゃんとバランスして入っているようなテキストを考えます。'{'、'}'を普通の文字(データ文字)として使いたいときはエスケープして'\{'、'\}'、'\'自体は'\\'にします(常識的なルールですね)。
例えば、
こんにちは、{板東トン吉}様。{{1月21日}にはご来店いただき、
まことにありがとうございます。}
この例のようなテキストの構造を図示するために、次のような図を使いましょう。
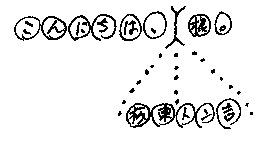
しかし、毎回こんな図を描くのは大変なので、次のような簡略化した線分図(?)も許します*1。
このような、バランスした括弧を含むテキストを、ネストしたテキストと呼びましょう。
- プログラミング課題 1: お好みのプログラミング言語を使って、与えられたテキスト(文字列)データが、正しく(well-formedな)ネストしたテキスト(nested text)であるかどうかを判定するプログラムを書いてください。
- プログラミング課題 2: 与えられたテキスト・データが正しくネストしたテキストであるとき(実際は、入力の形式を気にしなくてもよい)、エスケープしてない括弧('{'と'}')を取り去ってしまうプログラムを書いてください。
テンプレート処理
テンプレート処理はご存知ですか? このダイアリー(ブログ)内でも、「TrimPath JavaScript Templatesの紹介」とか、「DI(依存性注入)を白紙から説明してみる」などでテンプレート処理の説明をしています -- 必要があれば、予備知識としてザッと眺めておいてください。
例として、次のようなテキストを考えます。
こんにちは、{お客様名}様。{来店日}にはご来店いただき、
まことにありがとうございます。
構文的には、前節で導入したネストしたテキストに過ぎません(前節の例とわずかに変えてありますが)。しかしここでは、「お客様名」、「来店日」をデータ文字列ではなくて、テンプレート変数名(プレイスホルダー名)と解釈します。すると、このネストしたテキストはテンプレートだとみなせます。
さて、テンプレートを展開するにはコンテキストが必要です。コンテキストとは、テンプレート変数名と、その変数に対応する展開テキストを並べたデータです。とりあえず、コンテキストはJavaScript風の構文で記述しましょう。
var context = { "お客様名" : "板東トン吉", "来店日" : "1月21日" };
テンプレート処理を行う関数をprocessとすると、process(template, context) により展開の結果が返ります。今の例だと、「{お客様名}→板東トン吉」、「{来店日}→1月21日」という置き換えが起きて、次の出力が得られます。
こんにちは、板東トン吉様。1月21日にはご来店いただき、 まことにありがとうございます。
- プログラミング課題 3:(けっこう面倒だから、やらなくていいけど)上記の例を実行できるようなテンプレート処理プログラムを書いてみてください。テンプレート変数以外の場所で、特殊文字としての'{'、'}'は登場しないと仮定してけっこうです。(http://www.chimaira.org/docs/SampleVST.htm から sample-vst.zip をダウンロードするとテンプレート処理系として使えます。説明は http://d.hatena.ne.jp/m-hiyama/20060926/1159253903 にあります。)
[追記] 「JavaScriptによるテンプレート・モナド、すっげー簡単!」に、超手抜き(ソースが6行)なテンプレート処理系があります。[/追記]
ブロック、文字列、名前
'{'と'}'で囲まれた部分をブロックと呼ぶことにします。ネストしたテキストは、ブロックを含むことができて、ブロック内にさらにブロックを入れてもいいわけです。内部にそれ以上ブロックを含まないブロックを、特に末端ブロックと呼びましょう。
最初に挙げた例(下に再掲)で、ブロックをすべて列挙し、そのなかで末端ブロックを識別してみてください。(ブロックの数は、右括弧の数と一致するはず。)
こんにちは、{板東トン吉}様。{{1月21日}にはご来店いただき、
まことにありがとうございます。}
- プログラミング課題 4:(これも割と面倒)ネストしたテキストの中から、末端ブロックだけを抜き出して列挙するプログラムを書いてください。ストリーム処理だけでがんばるより、ツリー構造を作ってリーフノードをたどるほうが簡明でしょう。まー、好みもあるけどね。
- プログラミング課題 5: ネストしたテキストに対して、末端ブロック以外の'{'と'}'(エスケープしてない括弧)を取り去ってしまうプログラムを書いてください。
課題3課題2と似てますが、ずっとむずかしいですね。
さてところで、「テキスト」と「文字列(ストリング)」って2つの言葉って、どう違うのでしょう? 僕は、(プログラム処理の文脈では)同義だと思っています。強いて言えば、文字列だとメモリ上に乗っていそうで、テキストはファイルとかもあるのかな、と、その程度の使い分けでしょうか。それでは、「文字列」と「名前」の違いはどうでしょうか? これはたぶん、用途の違いでしょう。名前をデータとして見れば、それは文字列に過ぎませんが、何か他のデータを指し示したり、他のデータに置き換えることを想定していれば、「名前」と呼ぶのだと思います(もっと哲学的(?)な説明もあるでしょうが)。
話をもとに戻して; 末端ブロックの内容データはテキスト、すなわち文字列です。この文字列を単なるテキスト・データとみなすか、名前とみなすかは用途によって決まるわけで、構文上の区別はありません*2。ブロックの内容を名前とみなすときは、末端ブロックをテンプレート変数(プレイスホルダー)と呼ぶわけです。
フラット・テキストとテンプレート・テキスト
ネストしたテキストに対して、“ネストのレベル”って言えば、なんのことだか分かりますよね。左括弧'{'が続けて('}'に出会わずに)何個出現したかを勘定すれば、それがネストのレベルです。
- プログラミング課題 6:与えられたテキスト・データが正しくネストしたテキストであるとき(入力は正しいと仮定してよい)、そのネスト・レベルを求めるプログラムを書いてください。
ネストしたテキストtに対して、そのネスト・レベルを nestLevel(t) としましょう。nestLevel関数を使って、次の概念を定義します。
- tがフラット・テキスト ⇔ nestLevel(t) = 0
- tが浅くネストしたテキスト ⇔ nestLevel(t) ≦ 1
フラット・テキストと浅くネストしたテキスト(shallowly nested text)の概念に慣れるため、バラバラと雑多な事実を並べましょう。
- フラット・テキストは、浅くネストしたテキスト(の一種)である。
- 浅くネストしたテキストは、ネストしたテキスト(の一種)である。
- 浅くネストしたテキストに含まれるブロックは、すべて末端ブロックである。
- ブロックがあっても末端ブロックだけのネストしたテキストは、浅くネストしたテキストである。
- テンプレートとして適切なデータは、浅くネストしたテキストである。
- コンテキストの展開テキストとして適切なデータは、フラット・テキストである。
- tがフラット・テキストなら、どんなコンテキストcに対しても、process(t, c) = t (processはテンプレート処理関数)。
浅くネストしたテキストは、テンプレートとして適切なので、テンプレート・テキストとも呼ぶことにします。「浅くネストしたテキスト」と「テンプレート・テキスト」は同義ですが:
| 言葉 | 使う文脈 | 備考 |
|---|---|---|
| 浅くネストしたテキスト | 一般的な話 | ブロックの内容は文字データとみなす |
| テンプレート・テキスト | テンプレート処理の話 | ブロックの内容はテンプレート変数名とみなす |
多段階のテンプレート処理
これからちょっと面白い話になりますよ。
こんにちは、{お客様名}様。{来店日}にはご来店いただき、
まことにありがとうございます。
これは、先ほど例に出したテンプレートですが、これを3つのテンプレートに分けます。
- テンプレート1 -- メイン
{挨拶}{来店御礼}
- テンプレート2 -- 挨拶
こんにちは、{お客様名}様。
- テンプレート3 -- 来店御礼
{来店日}にはご来店いただき、
まことにありがとうございます。
今まで、テンプレート処理関数processは、テンプレートとコンテキストを引数に取るとしてきましたが、2つの引数が共にコンテキストであることも許すとします。さらに、コンテキストの展開テキストが再びテンプレートでもいいとします。例えば、次のコンテキストも許します。
// 展開テキストが再びテンプレート var context1 = { "挨拶" : "こんにちは、{お客様名}様。", "来店御礼" : "{来店日}にはご来店いただき、\nまことにありがとうございます。" }; |< 今までのprocessをprocessTemplateとすれば、新しいprocessは次のようになります。(processTemplateもprocessも再帰的展開処理は<em>しません!</em>) >|javascript| /* 第1引数はテンプレートまたはコンテキスト * 第2引数はコンテキスト */ function process(first, second) { if (typeof(first) == "string") { // 第1引数がテンプレートであるとき return processTemplate(first, second); } // そうでないときは、firstはコンテキストだと仮定する var result = {}; for (var key in first) { result[key] = processTemplate(first[key], second); } return result; }
さて、以上の状況で、次の式の結果はどうなるでしょう?
process("{挨拶}{来店御礼}", process(context1, {"お客様名" : "板東トン吉", "来店日" : "1月21日"}))
わかりにくい? もっとバラしましょうか。
var main = "{挨拶}{来店御礼}"; var context1 = { "挨拶" : "こんにちは、{お客様名}様。", "来店御礼" : "{来店日}にはご来店いただき、\nまことにありがとうございます。" }; var context2 = { "お客様名" : "板東トン吉", "来店日" : "1月21日" }; var newContext = process(context1, context2); var result = process(main, newContext);
さあ、resultには何が入るでしょうか? この問に答えられるなら、「多段階のテンプレート処理」がどんな意味かわかりますね。それと、次の2つの結果が同じであることも確認してください。(ここらへんが山場だから、よーく納得してね。)
- process(main, process(context1, context2))
- process(process(main, context1), context2)
第1引数がテンプレートであるprocessTemplateと、第1引数がコンテキストであるprocessContextを区別して書けば次の2つの結果が同じ。
- processTemplate(main, processContext(context1, context2))
- processTemplate(processTemplate(main, context1), context2)
蛇足
あんまり現実的じゃないけど、2つの引数が共にコンテキストであるprocessContextが先にあるならば:
/* 第1引数はテンプレートまたはコンテキスト * 第2引数はコンテキスト */ function process(first, second) { if (typeof(first) == "string") { // 第1引数がテンプレートであるとき var con = {}; con["main"] = first; var result = processContext(con, second); return result["main"]; } // そうでないときは、firstはコンテキストだと仮定する return processContext(first, second); }
素材を整理しよう
これで素材は全部出そろいました。今までに出てきた重要なデータや概念に記号を割り当てておきましょう。
- フラット・テキスト(無構造なデータ文字列)全体の集合をTで表します。断りなしにTextと言えばフラット・テキストのことなので「T」にしました。太字にするのは、固有名詞的な記号だからです。
- テンプレート・テキスト(浅くネストしたテキスト)全体の集合をTTで表します。
- ネストしたテキスト全体の集合をNTで表します。
T⊆TT⊆NTでした。NTの部分集合を一般的にA, B, Cなどで表します。とりあえずは、A, B, Cなどは名前の集合と思っていいでしょう*3。例えば、A = {"挨拶", "来店御礼"}, B = {"お客様名", "来店日"}のように考えてください。
テンプレート変数名(末端ブロックの内容)が、集合Aに含まれるテンプレート・テキストの全体をTempl(A)と書きます。A = {"挨拶", "来店御礼"}の例なら:
- Templ(A)のメンバーは、
{挨拶}、{来店御礼}以外のテンプレート変数を含まないテンプレート。ただし、必ずしもテンプレート変数を含む必要はない。
と、そう考えればいいでしょう。Templ(A) = Templ({"挨拶", "来店御礼"}) のメンバーの例を3つ挙げれば(文字列リテラルで表現):
"{挨拶}\n----\n{来店御礼}\n""なんでもストア「よろず」です。{来店御礼}""Hello, World."
同様に、Nest(A)は、末端ブロックの内容がAに含まれるような、ネストしたテキストの全体です。次が成立しますね(練習として、確認してください)。
- T⊆Templ(A)⊆Nest(A)
- A⊆B ならば、Templ(A)⊆Templ(B)、Nest(A)⊆Nest(B)
- 0が空集合なら、Templ(0)=T、Nest(0)=T (0の意味をよーく考えてみよう)
- Templ(T)=TT、Nest(T)=NT (落ち着いて、先入観を持たず、よーく考えてみよう)
(考えてもよく分からないときは、ココに解答があります。)
モナドに向かって突っ走れ!!
オッケ〜〜イッ(古っ)、準備完了。あとはこの状況からモナドを引っ張り出すだけ。モナドに関しては、「世界で一番か二番くらいにやさしい『モナド入門』」を見てください。特に、最後の節「そして、これがモナドだ」を。モナドの定義に関しては、「モナドの定義とか」が詳しいです。
「世界で一番か二番くらいにやさしい『モナド入門』」から引用すると:
モナドは次の3つで定義されます。
- 型Tから新しい型M(T)を創り出す型構成子M
- fun:T→M(S)という関数からext(fun):M(T)→M(S)という関数を作り出す関数(高階関数)である(M用の)ext
- 型Tの値を、M(T)型のデータにする関数である(M用の)unit
M, ext, unit は、一般論のための記号ですから、今回のケースに特殊化する必要があります。「型T」というのは、今回は「データの集合T」と考えればいいでしょう。型構成子はTemplとNestです。データ(なんらかのテキスト)の集合A(固有名詞のTと紛らわしいからTじゃなくてAを使う)からTempl(A)とNest(A)というデータの集合を構成する手順は既にあります。まずはTemplだけを相手にしましょう。
fun:A→Templ(B)という関数は、実はコンテキストですね。えっ、なにか不思議? コンテキストってのは、(JavaScript風の記法で)context1["挨拶"]とかcontext2["来店日"]とかして、名前に対応する展開テキストを提供するデータ構造でした。これに対応する関数を作って(あるいは関数でラップして)、context1("挨拶")、context2("来店日")の値を使ってもいいわけです。コンテキストの“名前=マップのキー”は、その意味/用法を忘れればテキスト・データに過ぎないから、コンテキストとは「テキスト・データ → 展開テキスト」って関数でしょ。
とあるテキスト・データ(気持ちとしては“名前”)の集合をAとしましょう。展開テキストはテンプレートでもいいことにしたのを思い出せば;展開テキストの集合は、適当な“名前”の集合Bを使ってTempl(B)と書けます。すると、コンテキストは A→Templ(B) という関数ですな。なんかモンクある?
次に、関数としてのコンテキスト con:A→Templ(B) を、 Templ(A)→Templ(B) へと拡張すること、これはズバリ、テンプレート展開処理そのもの。えっ、なにか不思議? A = {"挨拶", "来店御礼"}, B = {"お客様名", "来店日"}の例では、{挨拶}と{来店御礼}を含むテンプレート、すなわちTempl(A)のデータが、{お客様名}と{来店日}を含むテンプレート、すなわちTempl(B)のデータへと展開されたでしょう。これはつまり、con:A→Templ(B) から、拡張であるcon_ex:Templ(A)→Templ(B)が決まった、ってこと。なんかモンクある?
con_exを明示的に書けば、t∈Templ(A)に対して:
- con_ex(t) := processTemplate(t, data(con))
ここで、data(con) は、関数としてのコンテキストをデータに直したものです。関数をデータ化する高階関数dataは、前もって関数conに細工がないと実装できませんが、まー、高階関数dataは作れるものと仮定します。いっそ、processTemplateの第2引数は関数としてのコンテキストもOKだとして、
- con_ex(t) := processTemplate(t, con)
のほうがスッキリしますね。すると、関数conからcon_exを作り出す高階関数extは次のように書けるでしょう。
- ext(con) := λt.(processTemplate(t, con))
ラムダ記法の「λ」は、この機会に是非、誰かに聞くかどこかで調べてみてください。extの定義から、con_ex(t) = (ext(con))(t) = processTemplate(t, con) ですね。
- プログラミング課題 7:お好みの高階関数型言語(なーに、JavaScriptで十分)で、第2引数に関数を受け取るprocessTemplateと、関数としてのコンテキストを拡張する高階関数extを書いてください。実装言語/実装方法によっては、「関数としてのコンテキスト←→データとしてのコンテキスト」の変換には細工が必要です。
もうひとつ、モナドを構成する要素としてunitが必要です。これは展開効果が無いコンテキストを採用します。集合Aごとに、関数とみなしたコンテキスト unit_A:A→Templ(A) は、A = {"挨拶", "来店御礼"}のケースなら:
- unit_A("挨拶") = "{挨拶}"
- unit_A("来店御礼") = "{来店御礼}"
- それ以外の unit_A(x) は未定義
となります。unit_Aによるテンプレート展開は、結果的に何の効果もありません。processTemplate(t, unit_A) = t です。
バッチリ、モナドだぜぇ
まとめると:
- 集合Aのメンバー(名前と考えるとよい)をテンプレート変数名とするテンプレート・テキストの全体をTempl(A)とする。
- コンテキストconは、con:A→Templ(B) という関数だと考える。
- (ext(con))(t) = processTemplate(t, con)、ext(con):Templ(A)→Templ(B) として高階関数extを定義する。
- unit_A は、Aに含まれる名前をTempl(A)内に変数として埋め込む A→Templ(A) で定義する。以下、Aによらず単にunitとも書く。
「モナドの定義とか」を参考にすると、(Templ, ext, unit)がモナドであるためには次が成立する必要があります。
- (ext(unit))(t) = t (tはテンプレート・テキスト)
- (ext(con))(unit(x)) = con(x) (conはコンテキスト、xはテンプレート変数名)
- ext((ext(con2))・con1) = ext(con2)・ext(con1) (記号・は関数の合成/結合)
なんか複雑そうに見える三番目を示してみましょう。ext(con) := λt.(processTemplate(t, con)) というextの定義と、g・f := (λy.g(y))・(λx.f(x)) := λx.(g(f(x)) という関数合成の定義を使って、ラムダ計算を実行します。(計算が分かりにくいなら飛ばしてください。)
(ext(con2))・con1 = (λt.(processTemplate(t, con2)))・(λx.con1(x)) = λx.(processTemplate(con1(x), con2))) 左辺 ext((ext(con2))・con1) = λt.processTemplate(t, (ext(con2))・con1) = λt.processTemplate(t, λx.(processTemplate(con1(x), con2)))
ext(con1) = λt.processTemplate(t, con1) ext(con2) = λs.processTemplate(s, con2) 右辺 ext(con2)・ext(con1) = (λs.processTemplate(s, con2))・(λt.processTemplate(t, con1)) = λt.(processTemplate(processTemplate(t, con1), con2))
さてと、前のほう(「多段階のテンプレート処理」のところ)で、「process(t, process(con1, con2)) = process(process(t, con1), con2)」に相当する等式が出てますよね、これは次を意味します。
- どんなtに対しても、processTemplate(t, processContext(con1, con2)) = (processTemplate(processTemplate(t, con1), con2))
processContext(con1, con2) の値は、関数としてのコンテキストで、名前(キーと言ってもいい)xに対して (processContext(con1, con2))(x) = processTemplate(con1(x), con2) となるので、ラムダ記法で書けば、
- processContext(con1, con2) = λx.(processTemplate(con1(x), con2))
これを使って、等式を書き換えれば、
- processTemplate(t, λx.(processTemplate(con1(x), con2))) = (processTemplate(processTemplate(t, con1), con2))
これからただちに、目的の等式「左辺=右辺」が導かれます。練習に、一番目と二番目の等式も示してください(unitの定義と性質を思い起こせば、ほぼ自明)。
- プログラミング課題 8: 言語機能としてモナドをサポートしているプログラミング言語(そう多くはないでしょう :-))で、テンプレート・モナドを書いてみてください。あるいは、お好みの言語で、テンプレート・モナド機構をシミュレートしてください。どのくらい難しいか、僕は知りませんよ。
残りは脱兎のごとく
圏論とモナドの知識を仮定して、TemplとNestの関係を述べましょう。読み飛ばしてもけっこうですよ。
Templがモナド(正確には、ベースとなる関手の対象部分)になることは分かりました。Nestもモナドになります。Templの場合は、モナド単位による埋め込みを包含のようにみなして、A⊆Templ(A)⊆Templ(Templ(A))⊆… が真に増大するケースが多いのですが、Nestの場合は、Nest(Nest(A)) = Nest(A) なので、モナド乗法μA:Nest(Nest(A))→Nest(A) が恒等となり、Templより単純です。モナド乗法が恒等であるモナドはベキ等モナド(idempotent monad)と呼びますが、Nestはベキ等モナドの例です。
面倒だから、TemplをT、NestをNと略記することにして、T(T(A))をT2(A)のように累乗形式で書くことにします。A⊆T(A)⊆T2(A)⊆T3(A)⊆… の極限をT∞(A)で表しましょう。T∞(A)は、増大列の極限であると同時に、形式的に I(A)∪T(A)∪T2(A)∪T3(A)∪… というクリーネ・スター級数の形(Iは恒等)でも書けますから、T∞をT*と書いてもいいでしょう(細かいことは言わないことにして)。いずれにしても、定義から、T∞ = T* = N です。モナドNは、モナドTの無限累乗、あるいは有限積の無限和で構成されます*4。
Nのベキ等性 N・N = N は、T∞(T∞) = T∞、無限累乗をさらに無限累乗しても同じだからいいだろう、と(イイカゲンに)推測できます。同様に、T・N = T(T∞) = T∞ = N も推測できます。つまり、T(N(A)) = N(A)。N(A)をXと置くと T(X) = X なので、N(A)がTの不動点になっています。TからNの構成は、次の条件付き不動点方程式を解く手段なわけね。
- A⊆X (AはXに埋め込める)
- T(X) = X
ついでに言っておくと;テンプレート処理のモナドTemplは、項モナド(term monad)の一種で、フラット・テキストが基礎項(ground term)になっています。コンテキストcon:A→Templ(B) はKleisli圏の射 A→B で、process(con1, con2) は、Kleisli圏における結合 con1;con2 を与えます。Templのモナド乗法ηA:Templ(Templ(A))→Templ(A) は、プログラミング課題5のプログラムで与えられます。
最後に言っておきたいこと
ここまでに述べたことは、「モナドに似た構造が現れる」とか「モナドの考え方が使える」とかではなくて、完全なモナドそのものがそこに在る話です。テンプレート処理のように、よく使われる手法の背後にもモナドが存在し、現象の法則性を握っています。その現象を理解したり、処理系の設計/実装に対する整合的な方針を得るには、やはり背後に控える本質であるモナドを抽出すべきだ、と僕は思います。
今まで僕は、文書処理やXMLの文脈で、圏論やモナドを正面に出すことはほとんどしませんでした(気味悪がられるから)。しかし、圏論やモナドなしで何かを説明するのは非常に手間もかかるし、とても苦しいので、最近では、圏論をプロモートして、圏論の言葉で何かを語るほうがかえって労力が少ないのでは、と思ってます。
最近の書評でも引用した谷村さんの言葉を再掲:
トポロジーや圏論や微分幾何学は,素人には近寄りがたい「高級な数学」ではなく,この世界に生起する出来事を語るためのとても自然な言語であり,これを自分の言葉として活用できるようにしておくと,いろいろなことが生き生きと見えてきて楽しいですよ