「Java BlockingQueueで遊ぶ:パイプラインごっこ」の続きです。せっかくですから、もう少し遊んでみよう、っと。
持ち駒を少し増やす
ここだけの用語法ですが、データの湧きだし元を入力デバイス、データの吸い込まれる先を出力デバイスと呼びましょう。入力ストリームを加工して出力ストリームに書き出すプログラムはフィルターと呼びます(これは一般的な用語法)。ここでは、データは文字(Javaのchar、またはCharacter型)に限定します。
「Java BlockingQueueで遊ぶ:パイプラインごっこ」では、次のようなデバイス/フィルターを準備しました。
- 入力デバイス FileIn
- 出力デバイス StdOut
- フィルター Word
- フィルター Tolower
簡単なデバイス/フィルターをさらに4つ付け加えておきます。
- 出力デバイス FileOut
- 出力デバイス DevNull
- フィルター Toupper
- フィルター Copy
出力デバイスFileOutは、FileInのコードをコピーして、[Rr]eader→[Ww]riterと置換するとほぼ出来上がりです(細かい修正はありますが)。フィルターToupperも、Tolowerをコピーして、[Ll]ower→[Uu]pperという置換です。
出力デバイスDevNullは、Unixの/dev/null、Windowsならnulに対応するもので、データを捨てる目的で使います。フィルターCopyは、何もしないで入力をそのまま出力にコピーします。
追加したデバイスとフィルターは、どれもとても簡単なものですね。
teeは、T字のティー
Unixにteeというフィルターコマンドがあります。次のように使います。(wordやtolowerは、上記Javaプログラムと同じ働きをするフィルターコマンドだとします。)
word < input.txt | tee word.out.txt | tolower
teeは、引数で指定されたファイルword.out.txtに標準入力をコピーし、同時に標準出力にも標準入力をそのまま書き込みます。つまり、パイプラインの途中の結果をファイルに保存できるのです。この場合なら、wordの出力をword.out.txtに保存します。
teeの語源は英字のTです。直線状のパイプラインの一部に、T字接合器(Tジャンクション)を取り付けて分流(branch)するような感じだからです。
さて、このteeをJavaで書いたオモチャ・パイプラインで再現しましょう。直接teeを実装するのではなくて、少し一般性のあるDup(duplicate)というフィルターを書きましょう。ただし、Dupの出力は2つあるので、抽象クラスFilterをそのままは使えません。かっこ悪い方法ですが、とりあえずFilterのコードをコピーして手直しします(コピー&モディファイばっかしだな(苦笑))。
// Filter2.java abstract class Filter2 implements Runnable { protected In in; protected Out out1; protected Out out2; public Filter2(In in, Out out1, Out out2) { this.in = in; this.out1 = out1; this.out2 = out2; } public abstract void run(); // runnable public void start() { (new Thread(this)).start(); } } class Dup extends Filter2 { public Dup(In in, Out out1, Out out2) { super(in, out1, out2); } public void run() { int c; while ((c = in.getc()) != -1) { out1.putc((char)c); out2.putc((char)c); } out1.end(); out2.end(); } }
teeをJavaで実現してみる
次のシェルスクリプトと同じ働きをするプログラムを、Javaで書いてみます。
#!/bin/sh if [ $# -lt 1 ]; then echo "No arg." exit 1 fi word < $1 | tee word.out.txt | tolower
こんなん(↓)です。
// PipelineDemo2.java import java.io.*; class PipelineDemo2 { public static void main(String[] args) { if (args.length < 1) { System.err.println("No args."); System.exit(1); } String filename = args[0]; // input/output devices FileIn fileIn = new FileIn(filename); FileOut fileOut = new FileOut("word.out.txt"); StdOut stdOut = new StdOut(); // pipes Pipe pipe1 = new Pipe(); Pipe pipe2 = new Pipe(); // filters Filter word = new Word(fileIn, pipe1); Filter2 dup = new Dup(pipe1, pipe2, fileOut); Filter tolower = new Tolower(pipe2, stdOut); // start pipeline word.start(); dup.start(); tolower.start(); } }
言い忘れてましたが、サンプルを簡単にする目的で、発生する例外はすべてRunTime例外に変換してます。お行儀は良くないですが、例外処理がなくなってスッキリします。
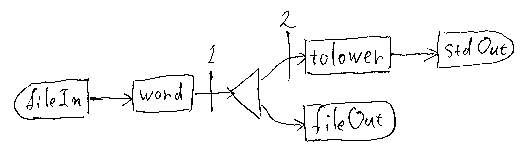
絵に描いてみる
PipelineDemo2のコードは特に複雑なものではありませんが、それでも、何をやっているか判読しにくいかもしれません。やっていることは、ちょっと変形したパイプラインの配管(組み立て、構築)と実行です。回路図みたいな絵に描いたらわかりやすいですよ。絵記号(アイコン、回路素子)は次のように約束します。
![]()
手書きの字が汚くヘタだってか、えーどうせヘタですよ! それで、パイプラインの絵は下のようになります。Javaソースコードと見比べてみてください。絵のなかの番号は、pipe1, pipe2に対応します。
もっと絵を描いてみる
今度は先に絵を描きましょう。
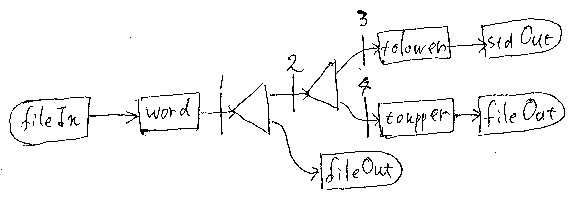
この絵をJavaに翻訳したものは、PipelineDemo3.java(別ウィンドウにテキストとして表示)にあります。このプログラムを実行すると:
- wordによる途中結果をword.out.txtに保存
- tolowerによる最終結果をコンソールに表示
- toupperによる最終結果をファイルtoupper.out.txtに保存
することになります。
Dupで分岐(二股に分流)した結果を別々のパイプラインに流すのは、Unixパイプラインの構文ではできません(プログラムで配管を書くならできます)*1。teeで分岐はできますが、分岐した片一方はファイルに限られますからね。
では、Dupのような分岐や、同時に走る2本以上のパイプラインを記述する簡潔な構文はあるのでしょうか? お客さん、いいコがいまっせ。「ETBダイアグラム」という記事をザザーッとスクロールしてみてください。このダイアリー・エントリーにある汚い絵と似たような絵があるでしょ。あるいは、もっとウニョウニョした回路図もどきが「スーパーポージング公理からスーパーポージング定理へ 図だけ」に描いてあったりします。
このような図、または図に対応する記号的表現が、分岐や平行パイプライン(図形的な平行のことで、並行実行のことではない)をうまく記述し、計算する方法を与えます。「いいコがいまっせ」とはこの方法のことです。このコの名前ですか? GSモノイド圏(GS Monoidal Categories)です。
配管の素材やら道具やら操作やら
今回Javaで書いたオモチャに出てくるクラス(デバイスまたはフィルター)と、GSモノイド圏における概念、記号(Corradini&amp;Gadducciに従う)を表にまとめておきましょう。
| Javaのクラス | 概念 | 記号 |
|---|---|---|
| Copy | 恒等射 (identity) | I1 |
| Dup | 重複器(duplicator) | ∇1 |
| DevNull | 放電器(discharger) | !1 |
| (書いてない) | 対称(symmetry)、交差(crossing) | X1,1 |
| パイプ、リダイレクト | 結合(composition) | ; |
| 入力ストリームの本数 | 域(domain) | dom |
| 出力ストリームの本数 | 余域(codomain) | cod |
| 平行に配置 | 和(モノイド演算) | + |
気が向いたら、もう少し複雑な配管/配線も紹介するかも。
*1:おっと、zshなら簡単に出来てしまいますね。word < in.txt > word.out.txt | tolower > /dev/tty | toupper > toupper.out.txt