Catyで何かしようとすると、スキーマ定義から始めます。スキーマ駆動なんです。スキーマ駆動の工程がどんな感じなのかをお伝えするため、割とリアリティがある実例を使います。細部は気にしないで全体の流れを感じ取ってください。
内容:
例題は林データ構造
「有向グラフにサイクルを作らない方法 -- レベル関数」において、有向グラフのサイクルを排除する話をしましたが、この方法が簡単に使えるのはグラフが木(ツリー)または木の集合体である林(forest)の場合です。例題として、林のデータ構造を扱うことにします。
林は何本か(0本でも1本でもよい)の木の集まりです。下の図を見てください。林のなかの木の本数を勘定すると4本です。ルートノードだけでも立派な木なのです。そして、林のなかのノードを勘定すると12個あります。林は場合により、単なるノードの集合と見ることもあるし、木の集合と見ることもあります。
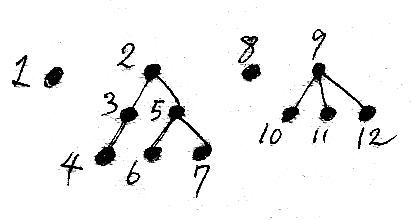
有向グラフとしての林をGとすると、ノードの集合はNode(G)で表しましょう。ルートノードの集合はRoot(G)とします。明らかに、Root(G)⊆Node(G) ですね。ルートノードと木は1:1に対応するので、Root(G)をGに含まれる木の集合の代わりに使えます。つまり、ルートノードにより木全体を代表させるわけです。a∈Root(G) のとき、aをルートとする木を Tree(a, G) としましょう。Tree(a, G) はもとの林Gの部分グラフなので、グラフの包含関係の意味で Tree(a, G)⊆G です。a, b∈Root(G)、a≠b ならば、Tree(a, G) と Tree(b, G) は共通部分がなく離れています。
上の図の例では:
- Node(G) = {1, 2, 3, ..., 12}
- Root(G) = {1, 2, 8, 9}
- G = Tree(1, G) + Tree(2, G) + Tree(8, G) + Tree(9, G) (「+」は直和)
- Node(Tree(1, G)) = {1}
- Node(Tree(2, G)) = {2, 3, 4, 5, 6, 7}
- Node(Tree(8, G)) = {8}
- Node(Tree(9, G)) = {9, 10, 11, 12}
このような林データ構造に対する操作(operation, manipulation)一式をWeb APIに仕立てるのが目標です。ただしここでは、Web APIの一歩手前までを説明します。
ノードのデータ型を定義する
各ノードは、ID(一意識別子)とコンテンツを持つとしましょう。
type ID = string(format="id");
type NodeData = {
@[readonly]
"id" : ID,
"content" : string?
};
念のために説明すると:
- ID型は文字列型ですが、そのフォーマットがIDとして相応しいものです。
- NodeData型は、JSONオブジェクト型です。
- @[readonly]はアノテーションで、idプロパティが読み取り専用であることを示します*1。idプロパティを書き換えることはできない、または書き換えようとしても無視されます。
- contentプロパティの値は文字列型です。このプロパティは省略可能です。
これだけだと木としての親子関係が記述できないので、次の型も定義します。
type IDREF = string(format="id");
type Relationship = {
"parent" : IDREF?,
"child" : [IDREF*]?
};
- IDREF型はID型と同じです。しかし用途が違うので違う型名を付けました。IDREFにより他のノードを参照します。
- Relationship型は、JSONオブジェクト型です。
- parentプロパティは、親ノードを参照するものです。省略された場合は「親なし」、つまりルートノードです。
- childプロパティは、子ノードのリストです。値が空なリスト[]、またはchildプロパティが省略された場合は末端ノードです。
Caty型システムでは、型の継承やミックス(mixin)をする方法が2つあります。集合論的な共通部分を取る演算子'&'と、オブジェクトのマージを行う演算子'++'です。今回は'++'を使います。'++'の意味はすぐ後に説明します。
type Node = NodeData ++ Relationship;
演算子'++'を使った定義は、次の定義と同値です。
type Node = {
// NodeData から
@[readonly]
"id" : ID,
"content" : string?,
// Relationship から
"parent" : IDREF?,
"child" : [IDREF*]?
};
ストレージ資源と例外
CatyではIOの対象となるような資源には名前が付いていて、アクセスするには明示的な宣言が必要です。林データ構造を実現するには、メモリ、ファイルシステム、キーバリューストア、関係データベースなどの、なんらかのストレージ資源が必要です。ここでは、ストレージ資源を特定せずに、storageというドーデモイイ名前で呼びます。
コマンド(Catyの処理実行単位)がストレージ資源にアクセスを要求するには次の宣言が必要です。
- 読み取りだけ reads storage
- 書き込みだけ updates storage
- 両方 uses storage
コマンドが例外を投げる可能性があるなら throws で宣言します。例外データ型は前もって定義しておきます。
type ExceptionCommonObj = {
// Message型は他で定義されているとする
"message" : Message, // エラーメッセージ
* : any? // 任意に拡張可能
};
/** 指定されたノードが存在しないとき */
@[exception]
type NodeNotFound = @NodeNotFound ExceptionCommonObj;
/** 指定された林が存在しないとき */
@[exception]
type ForestNotFound = @ForestNotFound ExceptionCommonObj;
/** 木としての制約を満たさなくなるとき */
@[exception]
type TreeViolation = @TreeViolation ExceptionCommonObj;
コマンドを定義してみる
いよいよ、APIの中核となるコマンドセットを定義します。Catyでは、コマンドの宣言もスキーマの一部です。
コマンドはパラメータ(引数)と入力と出力を持ちます。とりあえず実例を出してしまいましょう。
type NodeID = ID; /** ノードIDで指定されたノードを取得 */ command get [NodeID] :: void -> Node throws NodeNotFound reads storage;
- NodeID型はID型と同じですが、利用目的が違うので別名の定義をしています。
- getコマンドは、NodeID型の引数を1つ取ります。それはノードを指定するためです。
- getコマンドの入力の型はvoid型です。入力は事実上ありません。
- getコマンドの出力の型はNode型です。
- getコマンドは、NodeNotFound例外を投げる可能性があります。
- getコマンドは、storage資源を読み取り専用で使用します。
Webとの関係で言えば、パラメータは主にリクエストURLから取られる情報で、入力はPOSTやGETのリクエストボディから作られます。コマンドの出力は通常はレスポンスボディになります。
この例では、ノードを表すURLへのHTTP GETリクエストがgetコマンドにマップされることを想定しています。とはいえ、Web(URLとHTTP)とコマンドセットを結びつけるバインディング機構は全然別な所にあるので、コマンドセット設計の時点では、Webへのバインディングの詳細は考えなくてもかまいません。
「コマンドを定義する」と言いましたが、まだ宣言しているだけです。“動く処理”の実装はCatyスクリプトと実装言語(Python)を使います。例えば、Pythonクラス forest.command.Get によりgetコマンドを実装したなら、実装を指し示す refers で宣言します。
type NodeID = ID; /** ノードIDで指定されたノードを取得 */ command get [NodeID] :: void -> Node throws NodeNotFound reads storage refers python:forest.command.Get;
もっとコマンドを定義する
前節で「Webへのバインディングの詳細は考えなくてもかまいません」と述べましたが、これは程度問題で、Webへのバインディングが非常にやりにくいようなコマンドセットを作ってしまうと後で苦労します。一方で、「PUTかPOSTか?」とか「パスかクエリ文字列か?」とかは判断が微妙なときがあるし、さまざまな都合で変更されることも多いので、設計の初期で悩んでも仕方ないと思います。
今回の例題では、データ構造の操作が目的なので、コールベースのコレクションAPIをHTTPに乗せるような感覚で(あまりRESTっぽくなく)話を進めます。
getは定義できたので、putを定義します。putコマンドをHTTP PUTにバインドする心積もりです。
/** ノードIDで指定されたノードを上書きする */ command put [NodeID] :: Node -> Node throws [NodeNotFound, TreeViolation] uses storage;
- putコマンドは、NodeID型の引数を1つ取ります。それはノードを指定するためです。
- putコマンドの入力の型はNode型です。
- putコマンドの出力の型はNode型です。
- putコマンドは、NodeNotFound例外、TreeViolation例外を投げる可能性があります。
- putコマンドは、storage資源を読み書き両用で使用します。
このputコマンドを実装するのはけっこう面倒な話になりますが、今はそれを気にしないことにします。
HTTP PUTは、通常はリソースの新規作成にも使えますが、今回の例ではputコマンドでノードの作成はできません。なぜかと言うと、ノードIDの生成と管理を林(を実装したプログラム)の側で行うので、API利用者が新規ノードIDを指定できないのです。そこで、createコマンドを定義しましょう。
type ForestID = ID; /** 新しいノードを作成する */ command create [ForestID] :: string|void -> Node throws ForestNotFound uses storage;
- ForestID型はID型と同じですが、利用目的が違うので別名の定義をしています。
- createコマンドは、ForestID型の引数を1つ取ります。それはファクトリーである林を指定するためです。
- createコマンドの入力の型はstring型またはvoid型です。ノードのコンテンツの値を指定します。
- createコマンドの出力の型はNode型です。新しく作られたノードです。
- createコマンドは、ForestNotFound例外を投げる可能性があります。
- createコマンドは、storage資源を読み書き両用で使用します。
この例では、createで生成された直後のノードはどの木にも所属しない孤立ノードです。これはまた、ルートだけからなる木でもあるので、ノードの生成は林のなかに木(自明な木)を生成することになっています。ノードを他の木にぶら下げたり子を追加するには、ノードのparent, childプロパティを書き換えてからputします。
重いコマンドを分割してみる
putコマンドの実装が面倒になるのは、ノードのコンテンツ(conentプロパティ)と親子関係の両方が一度に変更されるからです。(例題では、コンテンツは単なる文字列ですが、コンテンツが複雑なデータのときを考えてみてください。)そこで、コンテンツの操作と親子関係の操作に分割してみましょう。
/** ノードのコンテンツを上書きする */ command put-content [NodeID] :: string|void -> Node throws NodeNotFound uses storage; /** ノードの親子関係を変更する */ command set-relationship [NodeID] :: Relationship -> Node throws [NodeNotFound, TreeViolation] uses storage;
set-relationshipに、綴り'put'じゃなくて'set'を使ったのは気分の問題です。
putの分割に倣ってgetも2つに分割してみます。
/** ノードのコンテンツを取得する */ command get-content [NodeID] :: void -> string|void throws NodeNotFound reads storage; /** ノードの親子関係を取得する */ command get-relationship [NodeID] :: void -> Relationship throws NodeNotFound reads storage;
コマンドを細かく分けるのがいつでもいいとは限りませんが、機能がヘビーなコマンドは複数のコマンドに分割すると分かりやすくなることがあります。
さて、あと残るはノードの削除です。単一のノードだけを削除する場合と、そのノード配下のサブツリーを全部削除する場合に分けて2つのコマンドにします。
/** 指定されたノードのみ削除する */ command delete-node [NodeID] :: void -> void throws NodeNotFound uses storage; /** 指定されたノードとサブツリーを削除する */ command delete-tree [NodeID] :: void -> void throws NodeNotFound uses storage;
ノードは他のノードと親子関係で繋がっているので、削除するときは親子関係のメンテナンスをしないといけません。けっこう大変です。
林操作APIのまとめ
今まで出てきたコマンドを表にまとめましょう。
| 名前 | 引数 | 入力 | 出力 |
|---|---|---|---|
| create | ForestID | string|void | Node |
| get | NodeID | void | Node |
| get-content | NodeID | void | string|void |
| get-relationship | NodeID | void | Relationship |
| put | NodeID | Node | Node |
| put-content | NodeID | string|void | Node |
| set-relationship | NodeID | Relationship | Node |
| delete-node | NodeID | void | void |
| delete-tree | NodeID | void | void |
一応CRUD(Create/Read/Update/Delete)操作は揃いました。この他に、林Gに対するNode(G)とRoot(G)を取得するために次のコマンドがあったほうが便利でしょう*2。
| 名前 | 引数 | 入力 | 出力 |
|---|---|---|---|
| list-all-nodes | ForestID | void | List<Node> |
| list-root-nodes | ForestID | void | List<Node> |
Webへのマッピングでは、引数のNodeIDとForestIDはリクエストパスに、入力と出力はHTTPのエンティティボディに入れればいいでしょう。HTTPメソッドの選択も特に迷うことはないですよね。
あとは、ハイパーリンクを活用して、一連の操作のナビゲーションを提供すれば、Webっぽくなります。ハイパーリンクとナビゲーションについては次の記事を参照してください。