この記事は、「ロマンティック数学ナイト@渋谷 #12」の事後サポート用の記事です。今週中に何度か更新(編集・追加)すると思います。
[追記 date="木曜・朝"]大きな編集・追加はまだしてません。ミスの修正、表現の変更はしました[/追記][追記 date="木曜・夜"]「中間のまとめと展望」以降を追加しました。でも、資料作製は未着手。[/追記][追記 date="金曜・夕刻"]資料を提出。「ホッジ分解」の節を追加。あと、「ホッジ分解のランキング問題への応用」が残ってますが、これは明日口頭で話せるかも。[/追記]
内容:
- この記事の目的
- 比較可能性グラフ
- 離散ド・ラーム理論のセットアップ
- ド・ラーム複体とド・ラーム・コホモロジー
- ド・ラーム複体の解釈
- 中間のまとめと展望
- 双対空間、チェーンと離散積分
- 内積と随伴線形写像
- 離散外解析/離散ベクトル解析
- 離散解析の4つの作用素
- ホッジ分解
- ホッジ分解のランキング問題への応用(見出しだけ)
この記事の目的
2018年8月11日開催の「ロマンティック数学ナイト@渋谷 #12」でショートプレゼンします。時間は数分なので、尻切れトンボになるのは目に見えています。なので、僕のプレゼンをお聞きいただいた後の確認や補足のために、この記事を準備しておきます。
現時点では、当日資料(スライド)を作ってないので、資料の作製に伴いこの記事にも手を加えるでしょう。フィックスするのは金曜日かな。(資料はその前に提出したいけど、締切に間に合うかな、どうかな? -- とか言い訳っぽく言っておく。)
この記事だけ読んでもあんまり分かんないかも知れません。でも、この記事とは別に、ホッジ・ランクの入門記事を書く可能性はあります。そうなれば、この記事は、入門記事に対する続き(第二章)という位置付けになります。
話のネタ元は次の論文です。
- Title: Statistical ranking and combinatorial Hodge theory (2009 v2)
- Authors: Xipaoye Jiang, Lek-Heng Lim, Yuan Yao, Yinyu Ye
- Pages: 42p.
- URL: https://arxiv.org/abs/0811.1067
この論文を忠実に紹介するわけではありません。使う用語、記号・記法も変えているところがあります。
事後サポートであることの意味は、既に話題と問題意識は理解されている前提で書く、ということです。ショートプレゼンで問題意識は説明できても、おそらく、方法と背景を述べる余裕はないでしょう。
本文内で、《…》 と書かれた用語は、この記事内で説明してないけど既知と仮定する言葉です。僕のショートプレゼン内で説明されているでしょう(そう期待します)。
比較可能性グラフ
G = (V, E) を有限無向単純グラフとします。その意味は:
- Vは、有限集合です。Vの要素を頂点〈vertex〉と呼びます。
- Eは、Vの2元部分集合の集合Pow2(V)の部分集合です。Eの要素を無向辺〈undirected edge〉、または単に辺〈edge〉と呼びます。(この記事内では、単に「辺」と言ったら無向辺です。)
Pow(X)はXのベキ集合(部分集合の集合)で、Pown(X)は基数(要素の個数)がnである部分集合の集合です。Gはグラフですが、辺に向きはなく、多重辺も自己ループ辺も認めません。
G = (V, E) を《ランキング問題》のモデルと考えるときは:
- 頂点は選択肢〈alternative〉と考えます。僕は評価対象と呼んでいます。
- 頂点Aと頂点Bが辺で結ばれている({A, B}∈E である)ときは、AとBは比較可能〈comparable〉だと言います。AとBが比較可能でない〈比較不能〉とは、種類が違うので比較がナンセンスだとか、比較する手段や比較用のデータがないとかです。
Gは幾何的形状を持つので、連結成分とか幾何的サイクル(1次元の有向な輪)とかを定義できます。
ときに、Gの頂点の集合Vに全順序〈total order〉を入れます。この全順序はまったく便宜的なものです。頂点に通し番号を付けて、その番号で順序付けしてもいいし、頂点の個数が少ないなら英字一文字で頂点にラベルして、アルファベット順で順序付けしてもいいです。なんでもいいです、便宜的なので。
A, B, C∈V、{A, B, C}∈Pow3(V) として、三元集合{A, B, C}が三角形〈triangle〉だとは、次を満たすことです。
- {A, B}∈E かつ {B, C}∈E かつ {A, C}∈E
三辺形と言ってもいいですね。三角形と三辺形は同義語として使います。辺に向きがないので、三角形も向き〈orientation〉を持たないことに注意してください。

Gのすべての三角形からなる集合をT(T⊆Pow3(V))とします。GからTは一意に決まります。三角形の集合をよく使うので、最初からグラフの構成素に入れて G = (V, E, T) としておきます。(Tを落としても、V, Eから再構成できますが、入れておけば便利。)
三角形の集合を添えた有限無向単純グラフ G = (V, E, T) を、《ランキング問題》の観点からは比較可能性グラフ〈comparability graph〉と呼びます。
離散ド・ラーム理論のセットアップ
比較可能性グラフは、《離散ド・ラーム理論》を載せるための台空間〈underlying space〉と言えます。比較可能性グラフ G = (V, E, T) 上にド・ラーム複体を構成しましょう。なお、ド・ラーム複体やホッジ分解に関しては次の記事で説明しています。
上記記事で、離散的(組み合わせ的)なケースを紹介しているのですが、「離散」の意義が違います。上記記事では、
- 連続な状況に対する近似としての離散
を想定しています。今回は、
- 最初から離散な状況
です。
さて、まず G = (V, E, T) に対する組み合わせ複体(単体複体)K(G)を定義しましょう。以下、K = K(G) と略記します。一般的に「単体複体とは何であるか」は気にしなくていいです。比較可能性グラフGから作ったKを単体複体〈simplicial complex〉と呼ぶ、ということだけ知ってれば今は十分です*1。単体複体Kは、K0, K1, K2 という3つの有限集合から構成されます。
- K0 := V
- K1 := {(A, B)∈V×V | {A, B}∈E}
- K2 := {(A, B, C)∈V×V×V | {A, B, C}∈T}
集合Kkの要素をk-セル〈k-cell〉と呼びます*2。k-セル(k = 0, 1, 2)と、頂点/辺(無向辺)/三角形を同じ意味で使うときが多いのですが、ここでは同じ意味とは限りません。
- 頂点Aと、0-セルAは同じ意味。
- 無向辺{A, B}に対して、2つの1-セル (A, B), (B, A) が対応する。
- 三角形{A, B, C}に対して、6つの2-セル (A, B, C), (A, C, B), (B, A, C), (B, C, A), (C, A, B), (C, B, A) が対応する。
0-セルは頂点そのもの、1-セルと2-セルは辺・三角形の頂点に順番を付けたものです。頂点の順番付け〈oerdering〉が違えば、台図形〈underlying shape〉が同じでも違うセルです。
Kk(k = 0, 1, 2)上のR値関数で、交代的〈反対称〉なものを考えます。交代的とは次のことです。
- f:K0→R が交代的 :⇔ なんでもいい(特に条件なし)
- ω:K1→R が交代的 :⇔ (A, B)∈K1 に対して、ω(A, B) = -ω(B, A) が成立する。
- σ:K2→R が交代的 :⇔ (A, B, C)∈K2 に対して、以下の等式が成立する。
- σ(A, B, C) = σ(A, B, C) (自明)
- σ(A, C, B) = -σ(A, B, C)
- σ(B, A, C) = -σ(A, B, C)
- σ(B, C, A) = σ(A, B, C)
- σ(C, A, B) = σ(A, B, C)
- σ(C, B, A) = -σ(A, B, C)
置換の符号という概念を使えば一般的な定義ができますが、k = 0, 1, 2 だけなので一般論は不要です。
Ω0(K), Ω1(K), Ω2(K) を次のように定義します。
- Ω0(K) := {f:K0→R | fは交代的(特に条件なし)}
- Ω1(K) := {ω:K1→R | ωは交代的}
- Ω2(K) := {σ:K2→R | σは交代的}
Ωk(K) (k = 0, 1, 2)は自然にR上のベクトル空間の構造を持つので、以下、ベクトル空間として扱います。ベクトル空間Ωk(K)の要素をk-コチェーン〈k-cochain〉またはk-形式〈k-form〉と呼びます。この呼び方の背景を知りたい方は:
具体的な計算をするために、ベクトル空間の基底を固定します。そのために、比較可能性グラフGの頂点集合Vに全順序を入れます。この全順序は、計算の都合のために便宜的・人為的に入れるもので、構造的・内在的な意味は何もないことに注意してください。
V = (V, ≦) を便宜的・人為的に定めた全順序構造とします。この全順序構造のもとで:
- 任意の0-セルAを、強単調0-セルと呼ぶ
- A < B である1-セル(A, B)を、強単調1-セルと呼ぶ
- A < B < C である2-セル(A, B, C)を、強単調2-セルと呼ぶ
強単調k-セル〈strongly monotonic k-cell〉(k = 0, 1, 2)は、セルを {0, ..., k}→V という全順序集合のあいだの写像と考えたときに強単調(i < j ならば f(i) < f(j))なことです。強単調なk-セルに限定すると:
- 比較可能性グラフGの頂点と、単体複体Kの強単調0-セルは、1:1対応する。
- 比較可能性グラフGの辺と、単体複体Kの強単調1-セルは、1:1対応する。
- 比較可能性グラフGの三角形と、単体複体Kの強単調2-セルは、1:1対応する。
強単調k-セル全体の集合をK<kとします。今言ったことから、V $`\stackrel{\sim}{=}`$ K<0, E $`\stackrel{\sim}{=}`$ K<1, T $`\stackrel{\sim}{=}`$ K<2。
ベクトル空間Ωk(K) (k = 0, 1, 2)の基底を、強単調k-セルでインデックスして定義しましょう。定義には型付きラムダ記法(ココを参照)を使います。
A∈K<0 に対して、
δA :=
λX∈K0.(if (X = A) then 1 else 0)
(A, B)∈K<1 に対して、
δA,B :=
λ(X, Y)∈K1.(
if ((X, Y) = (A, B)) then 1
elseif ((X, Y) = (B, A)) then -1
else 0
)
(A, B, C)∈K<2 に対して、
δA,B,C :=
λ(X, Y, Z)∈K2.(
if (
(X, Y, Z) = (A, B, C) or
(X, Y, Z) = (B, C, A) or
(X, Y, Z) = (C, A, B)
) then 1
elseif (
(X, Y, Z) = (A, C, B) or
(X, Y, Z) = (B, A, C) or
(X, Y, Z) = (C, B, A)
) then -1
else 0
)
今定義したδ達は、クロネッカーのデルタとエディントンのイプシロンを混ぜてカリー化した*3ようなものですが、記号はデルタを使いました。強単調k-セルでインデックスされたδ達は、ベクトル空間Ωk(K) (k = 0, 1, 2)の基底となるので、次のような表示が可能です。
$` f \,=\, \sum_{A\in K^{<}_0} f(A)\delta_{A}`$
$` \omega \,=\, \sum_{(A, B)\in K^{<}_1} \omega(A, B)\delta_{A,B}`$
$` {\bf \sigma} \,=\, \sum_{(A, B, C)\in K^{<}_2} {\bf \sigma}(A, B, C)\delta_{A,B,C}`$
あるいは、A, B, C∈V であるのは了解されているとして:
$` f \,=\, \sum_{A} f(A)\delta_{A}`$
$` \omega \,=\, \sum_{A < B} \omega(A, B)\delta_{A,B}`$
$` {\bf \sigma} \,=\, \sum_{A < B < C} {\bf \sigma}(A, B, C)\delta_{A,B,C}`$
行きがかり上、今定義したΩk(K)の基底をデルタ基底〈delta basis〉と呼びましょう。Ωk(K)のデルタ基底は、強単調k-セルの集合K<kでインデックスされます。デルタ基底の概念は、最初に人為的に決めた全順序 (V, ≦) に依存しますが、頂点集合Vの全順序を固定した上で、標準的〈canonical〉な基底と言えます。
今後、ベクトル空間Ωk(K) (k = 0, 1, 2)に関する具体的計算は、すべてデルタ基底を用いて行います。記号δが、クロネッカーのデルタとは少し違うことには注意してください。
ド・ラーム複体とド・ラーム・コホモロジー
離散の場合の用語法をどうするか悩むのですが、「ド・ラーム・コホモロジーとホッジ分解のオモチャ (2/2) // 多様体から線形代数へ」で決めた用語を使うことにします。以下に用語対応表を再掲します。(今、用語の意味が分からなくてもかまいません。)
| 連続(多様体)の場合 | 離散(比較可能性グラフ)の場合 |
|---|---|
| 多様体 M | 単体複体 K |
| 特異チェーンの空間 Ck(M) | 組み合わせチェーンの空間 Ck(K) |
| 微分形式の空間 Ωk(M) | 組み合わせコチェーンの空間 Ωk(K) |
| 境界作用素 ∂k:Ck(M)→Ck-1(M) | 境界作用素 Bk:Ck(K)→Ck-1(K) |
| 外微分作用素 dk:Ωk(M)→Ωk+1(M) | 余境界作用素 Dk:Ωk(K)→Ωk+1(K) |
| ベルトラミ作用素 δk:Ωk(M)→Ωk-1(M) | ベルトラミ作用素 Ak:Ωk(K)→Ωk-1(K) |
| ラプラシアン Δk:Ωk(M)→Ωk(M) | ラプラシアン Lk:Ωk(K)→Ωk(K) |
| 調和形式の空間 Θk(M) = Ker(Δk) | 調和コチェーンの空間 Θk(K) = Ker(Lk) |
ただし、《ランキング問題》に固有な言葉も同義語として併用します。
では、余境界作用素(外微分作用素に相当)を定義しましょう。D0:Ω0(K)→Ω1(K) と D1:Ω1(K)→Ω2(K) を次のように定義します。
- f∈Ω0(K) に対して、
(D0(f))(A, B) = f(B) - f(A)
D0(f)∈Ω1(K) - ω∈Ω1(K) に対して、
(D1(ω))(A, B, C) = ω(B, C) - ω(A, C) + ω(A, B)
D1(ω)∈Ω2(K)
D0(f), D1(ω) が交代的〈反対称〉であることを確認する必要があります(やってください)。そして、次の事実が極めて重要です。'$`\circ`$'は作用素の結合〈合成〉、'0'はゼロ写像です。等式は簡単に確認できますね。
- D1$`\circ`$D0 = 0 : Ω0(K)→Ω2(K)
上の等式から、Ker, Im を線形写像の核空間、像空間として、次が成立します。
- Im(D0) ⊆ Ker(D1)
D0とD1にゼロ写像を付け加えた線形写像の列
- O -(ゼロ写像)→ Ω0(K) -(D0)→ Ω1(K) -(D1)→ Ω2(K) -(ゼロ写像)→O
を、単体複体Kの(あるいは比較可能性グラフGの)ド・ラーム複体〈de Rham complex〉と呼びます*4。そして、ド・ラーム複体の Ker/Im をとった以下のベクトル空間の列を、単体複体Kの(あるいは比較可能性グラフGの)ド・ラーム・コホモロジー〈de Rham cohomology〉と呼びます。
- H0(K) := Ker(D0)/O $`\stackrel{\sim}{=}`$ Ker(D0)
- H1(K) := Ker(D1)/Im(D0)
- H2(K) := Ω2(K)/Im(D1)
それぞれのベクトル空間Hk(K)をk次のド・ラーム・コホモロジー空間〈de Rham cohomology space of degree k〉といい、コホモロジー空間の要素をコホモロジー・クラス〈cohomology〉と呼びます。もっとも、0次のコホモロジークラスは、もとの空間Ω0(K)の要素とみなせるので、クラス(同値類)っぽくないですが。
《ランキング問題》の文脈では、今まで出てきた集合・空間の要素を、次のように呼びます。
- A∈K0 : 選択肢、評価対象
- (A, B)∈K1 : 比較可能ペア〈comparable pair | pair-wise comparison data〉(比較される二者)
- (A, B, C)∈K2 : 比較可能トリプル〈comparable triple | triple-wise comparison data〉(A, B, C 3つの評価対象と、(B, C), (A, C), (A, B) の3つの比較可能ペア)
- f∈Ω0(K) : スコア関数〈score function〉
- ω∈Ω0(K) : ペア選好形式〈pair-wise preference form〉(二者間で、どっちを選好〈prefer〉するかの値)
- σ∈Ω0(K) : トリプル矛盾形式〈triple-wise inconsistency form〉(三者間の比較に矛盾があるかどうかを示す値)
「ペア」を「二者」または「二者間」、「トリプル」を「三者」または「三者間」ともいいます。例えば、二者間選好形式、三者間矛盾形式という言葉を使います。
ド・ラーム複体の解釈
比較可能性グラフGから作られた単体複体Kに対して、ド・ラーム複体 O→Ω0(K)→Ω1(K)→Ω2(K)→O が定義できました。このド・ラーム複体を、《ランキング問題》の観点から解釈してみます(諸々の呼び名だけは前節最後で紹介しました)。
比較可能性グラフGは、問題の定式化の幾何的下部構造〈underlying geometric space〉を与えます。Gのトポロジカルな性質は、単体複体Kに、さらにド・ラーム複体Ωk(K)にと反映されるので、Gのトポロジカルな性質が問題全体を支配することになります。
ド・ラーム複体の0-形式〈0-コチェーン〉は、頂点集合V上で定義された実数値関数で、これが選択肢〈評価対象〉を(相対比較ではなくて)大域的に絶対比較した結果であるスコア関数となります。スコア関数fがあれば、次のようにしてV上にプレ順序(順序の公理から反対称律を取り除いた関係)が入ります。
- A $` \preceq`$ B :⇔ f(A) ≦ f(B)
左辺の'≦'は実数の大小順序です。こうして定義されるプレ順序'$` \preceq`$'は、便宜的・人為的に入れたV上の全順序'≦'とは別物で、何の関係もありません。fから決まるV上のプレ順序が、スコア関数による順位〈rank | ランク〉です。プレ順序なので、同順位(甲乙つけがたい)を認めます。
我々が特に注目するのはΩ1(K)の要素、1-形式です。比較可能なペア(順序対)(A, B)に対して1-形式は、「Aに対してBが、どのくらい好ましいか」を表す選好値〈preference value〉を割り当てます。「AとBを比べたとき、Bをどのくらい余計に推すか」でもあるので推し値と言ってもいいかも知れません。
選好値を{-1, 0, 1}に限ると、単純な二者比較(程度は考えない)になりますが、ここでは任意の実数値を許すので、選好(推し)の程度を定量的に表現できます。選好値を0に設定すれば「甲乙つけがたい」ですが、これは比較不能とは違います。比較不能はGのトポロジカルな性質で、選好値0はG上の1-形式の特性です。
今述べた事情により、1-形式を二者間選好形式〈pair-wise preference form〉、あるいは単に選好形式〈preference form〉と呼ぶわけです。
スコア関数fがあると、それに余境界作用素D0を作用させたD0(f)(しばしばDfと略記される)は二者間選好形式です。比較可能ペア(A, B)に対する選好値は f(B) - f(A) なので、スコアの差分です。Dfの形である選好形式から、スコア関数fを再現できます。そのためには、比較可能性グラフG上のパスに沿った“線積分”(離散的なもの、計算は総和)を求めればいいのです。
ベクトル解析との類似性から言うと、スコア関数はポテンシャルに相当します。ポテンシャルの勾配〈gradient〉として得られた場から、線積分により、定数の差を除けばポテンシャルを回復できます。積分定数の個数は、下部構造である多様体の連結成分の個数と同じでした。比較可能性グラフ上の離散線積分でも同様で、比較可能性グラフGの連結成分の個数だけ積分定数が出てきます。比較可能性からの同値関係でグループ分けした各ジャンル(同値類=連結成分)ごとに、積分定数=スコア関数の基準ゼロ値を任意に選べます*5。
任意の微分形式/ベクトル場がポテンシャルの勾配として得られるとは限らないのと同様に、任意の選好形式がスコア関数の差分として得られるとは限りません。離散線積分から関数が得られるとは限らないのです。もっと精密な分析が必要です。そのために、分析の道具を準備しますが、先に進む前に中間まとめ(次節)。
中間のまとめと展望
今までのおさらい; 我々の出発点は、有限無向単純グラフ G = (V, E) でした。これに、三角形の集合Tを添えて、G = (V, E, T) として、2次元の幾何的対象と考えました。G(《ランキング問題》の観点からは比較可能性グラフ)は、2次元の多様体と類似性があると期待できます。
実際、2次元の(なめらかでコンパクトな)多様体と三角形を添えた有限無向単純グラフには強い類似性があります。《ランキング問題》、《ホッジ・ランク》の理解のために多様体についての知識は必須ではありませんが、既にご存知の方のために、多様体=連続の場合と離散の場合の対応関係を示します(下の表)。下の表内で、T(M) は多様体Mの接バンドル、V∧W はベクトル空間VとWの外積です。
| 離散の場合 | 連続の場合 |
|---|---|
| 有限無向単純グラフ+三角形 G | 2次元コンパクト多様体 M |
| Gの頂点 A∈V (頂点=0-セル) | Mの点 p∈M |
| Gの1-セル (A, B)∈V×V | Mの接ベクトル(線素) Xp∈Tp(M) |
| Gの2-セル (A, B, C)∈V×V×V | Mの面素(無限小) Sp∈Tp(M)∧Tp(M) |
| 単体複体 K = K(G) | - |
| 0-形式の空間 Ω0(K) | 0-微分形式の空間 Ω0(M) |
| 1-形式の空間 Ω1(K) | 1-微分形式の空間 Ω1(M) |
| 2-形式の空間 Ω1(K) | 2-微分形式の空間 Ω2(M) |
| 余境界作用素 D0:Ω0(K)→Ω1(K) | 外微分作用素 d0:Ω0(M)→Ω1(M) |
| 余境界作用素 D1:Ω1(K)→Ω2(K) | 外微分作用素 d1:Ω1(M)→Ω2(M) |
| ド・ラーム複体 Ωk(K)→Ωk+1(K) | ド・ラーム複体 Ωk(M)→Ωk+1(M) |
| ド・ラーム・コホモロジー Hk(K) | ド・ラーム・コホモロジー Hk(M) |
2次元多様体Mを三角形分割すれば、Mから単体複体 K(M) を作れますが、グラフGが多様体の近似というわけではないので、K(G) ←→ K(M) のような対応は考えないことにします。つまり、K = K(G) に直接対応する連続バージョンはないとします。
G = (V, E, T) を2次元の幾何的対象とみなした図形(単体複体Kの幾何実現)はありますが、これが2次元多様体となるとは限りません。むしろ、たいていは多様体じゃないです。上に挙げた類似性は、k-形式(k-コチェーンとも呼ぶ)のベクトル空間Ωk(-)とそのあいだの作用素(線形写像)のレベルでより顕著です。つまり、抽象線形代数に持ち込んでしまえば、ほぼ同じ代数的構造を持ちます。
「G = (V, E, T) と2次元コンパクト多様体Mの類似性」は我々の指導原理(アイディアの源泉)ですが、M上にはリーマン計量が載り、外微分解析〈exterior differential calculus〉/ベクトル解析〈vector calculus 〉ができて、ホッジ理論〈Hodge theory〉が展開できます。これらの概念の離散バージョンを作ることが次の目標になります。
双対空間、チェーンと離散積分
比較可能性グラフ G = (V, E, T) において、Vは有限集合でした、E⊆Pow2(V) も有限で、T⊆Pow3(V) も有限、K1⊆V×V, K2⊆V×V×V も有限です。cardを集合の基数をとる関数だとして、
- dim(Ω0(K)) = card(V)
- dim(Ω1(K)) = card(K<1) = card(E)
- dim(Ω2(K)) = card(K<2) = card(T)
なので、Kの(Gの)ド・ラーム複体に出現するベクトル空間はすべて有限次元です。したがって、有限次元実数係数の線形代数が適用できます。これから、双対空間〈双対ベクトル空間〉の議論が出てきますが、次の記事が多少は参考になるかも。
さて、まず、k-形式(k-コチェーンともいう)の空間Ωk(K)の双対空間をCk(K)と書き、Ck(K)の要素をk-チェーン〈k-chain〉と呼びます。kはチェーンの次元〈dimension〉または次数〈degree〉と呼びます。各次元のチェーンを次のように表すことにします。
- 0-チェーン : P, Q, R (英字大文字)
- 1-チェーン : a, b, c (英字小文字)
- 2-チェーン : s, t, u (英字小文字太字)
もとの空間と双対空間のあいだの標準ペアリング〈canonical pairing〉(「双対ベクトル空間、これくらい知ってればイインジャナイ // 標準双対ベクトル空間」参照)は <-|->k(kは次数)と書きます。つまり:
- <P|f>0 = P(f) (P∈C0(K), f∈Ω0(K))
- <a|ω>1 = a(ω) (a∈C1(K), ω∈Ω1(K))
- <s|σ>2 = s(σ)(s∈C2(K), σ∈Ω2(K))
たいてい、<-|->k:Ck(K)×Ωk→R のkは省略します。
我々のストーリーでは、k-コチェーンの空間Ωk(K)を先に定義したので、k-チェーンの空間Ck(K)を双対空間として定義しました。しかし、Ck(K)を先に定義すれば、Ωk(K)がその双対空間になります。もとの有限次元ベクトル空間とその双対空間は対等なので、どっちが先でも大丈夫です。差別しないで、公平〈unbiased〉に扱いましょう。
k-コチェーン〈k-形式〉の空間Ωk(K)には、標準的な基底であるデルタ基底がありました。デルタ基底の双対基底を便宜上ガンマ基底〈gamma basis〉と呼び、次のように表します。
- γA : デルタ基底との関係 <γA|δX>0 = if (A = X) then 1 else 0
- γA,B : デルタ基底との関係 <γA,B|δX,Y>1 = if (A = X かつ B = Y) then 1 else 0
- γA,B,C : デルタ基底との関係 <γA,B,C|δX,Y,Z>2 = if (A = X かつ B = Y かつ C = Z) then 1 else 0
ガンマ基底も、K<0, K<1, K<2 でインデックスされた基底です。ガンマ基底によるk-チェーンの展開は次のようになります。
$` P \,=\, \sum_{A\in K^{<}_0} P_A\gamma_{A}`$
$` a \,=\, \sum_{(A, B)\in K^{<}_1} a_{A, B}\gamma_{A,B}`$
$` {\bf s} \,=\, \sum_{(A, B, C)\in K^{<}_2} {\bf s}_{A, B, C}\gamma_{A,B,C}`$
ガンマ基底の要素 γA, γA,B, γA,B,C を、強単調k-セル A, (A, B), (A, B, C) と同一視してしまい、次のようにも書きます。
$` P \,=\, \sum_{A\in K^{<}_0} P_A A`$
$` a \,=\, \sum_{(A, B)\in K^{<}_1} a_{A, B} (A, B)`$
$` {\bf s} \,=\, \sum_{(A, B, C)\in K^{<}_2} {\bf s}_{A, B, C} (A, B, C)`$
あるいは、A, B, C∈V であるのは了解されているとして:
$` P \,=\, \sum_{A} P_A A`$
$` a \,=\, \sum_{A < B} a_{A, B} (A, B)`$
$` {\bf s} \,=\, \sum_{A < B < C} {\bf s}_{A, B, C} (A, B, C)`$
こう考えると、標準ペアリングは次のように展開できます。
$`\langle P \mid f \rangle \,=\, \langle \sum_{A} P_A A \mid f\rangle \,=\, \sum_{A} P_{A}f(A)`$
$`\langle a \mid \omega \rangle \,=\, \langle \sum_{A < B} a_{A,B} (A, B) \mid \omega \rangle \,=\, \sum_{A < B} a_{A,B}\omega(A, B)`$
$`\langle {\bf s} \mid {\bf \sigma} \rangle \,=\, \langle \sum_{A < B < C} {\bf s}_{A,B, C} (A, B, C) \mid {\bf \sigma} \rangle \,=\, \sum_{A < B < C} {\bf s}_{A,B,C}{\bf \sigma}(A, B, C)`$
計算の途中で <A|f> = f(A) などとしています。これは頂点Aと頂点Aにおける求値作用〈evaluation〉を同一視しているわけで、A|→<A|-> はゲルファント変換です -- 詳しくは「双対ベクトル空間、これくらい知ってればイインジャナイ // 二重双対空間」を参照。
今述べた同一視のもとで、k-チェーンとは、k-セル(頂点、頂点の順序ペア、頂点の順序トリプル)の線形結合だと言えます。1次の標準ペアリング <a|ω>1 は1-形式の離散線積分、2次の標準ペアリング <s|σ>2 は2-形式の離散面積分を与えます。
離散線積分/面積分に関して、ストークスの定理とポアンカレの補題が成立します。境界作用素 Bk:Ck(K)→Ck-1(K) をガンマ基底を使って次のように定義します。
- B2(γA,B,C) = γB,C - γA,C + γA,B
- B1(γA,B) = γB - γA
定理の記述は次のようになります。
- ストークスの定理 1-2次元: <B2s|ω> = <s|D1ω>
- ストークスの定理 0-1次元: <B1a|f> = <a|D0f>
- ポアンカレの補題: 単一の三角形 {A, B, C} に関して、この三角形だけから作った単体複体をLとすると、Lのド・ラーム・コホモロジーはすべての次数でゼロ空間になる。i.e. Hk(L) = O (k = 0, 1, 2)。
内積と随伴線形写像
今まで、k-形式〈k-コチェーン〉の空間Ωk(K)に内積はありませんでした。内積を入れましょう。Ωk(K)に内積を入れることは、連続(多様体)の場合にリーマン計量を与えることに相当します。
ここでは、もっとも簡単な形の内積を考えます。一番単純な内積を採用しても、実用的モデルとして十分使えます。
$` (f|g)_0 \: :=\, \sum_{A \in K^{<}_0} f(A)g(A) `$
$` (\omega|\rho)_1 \: :=\, \sum_{(A, B) \in K^{<}_1} \omega(A, B)\rho(A, B) `$
$` ({\bf \sigma}|{\bf \tau})_2 \: :=\, \sum_{(A, B, C) \in K^{<}_2} {\bf \sigma}(A, B, C){\bf \tau}(A, B, C) `$
この内積により、デルタ基底は正規直交基底になります。逆の言い方をすれば、デルタ基底を正規直交基底にする内積を入れたのです。
有限次元ベクトル空間においては、内積を入れると、内積を入れた空間とその双対空間のあいだの線形同型が誘導されます。今の場合、次の同型が誘導されます。
- Ω0(K) $`\stackrel{\sim}{=}`$ C0(K)
- Ω1(K) $`\stackrel{\sim}{=}`$ C1(K)
- Ω2(K) $`\stackrel{\sim}{=}`$ C2(K)
この同型も非常に単純で、デルタ基底とガンマ基底の1:1対応(下)を線形拡張したものです。
- δA ←→ γA
- δA,B ←→ γA,B
- δA,B,C ←→ γA,B,C
この「デルタ←→ガンマ 対応」は、単純で自然なため、しばしばΩk(K)とCk(K)が区別できなくなります。これは良い点(話が単純になる)もあり、悪い点(違うものを混同する)もあります。区別はしながらも、ほとんど同じだと考えましょう。
一般に、内積空間のあいだの線形写像があると、逆向きの随伴線形写像を作ることができます。Ωk(K)達に内積が入れば、ド・ラーム複体の余境界作用素 Dk:Ωk(K)→Ωk+1(K) の随伴線形写像を定義できるので、それらを Ak:Ωk→Ωk-1 とします。次のような感じになります。
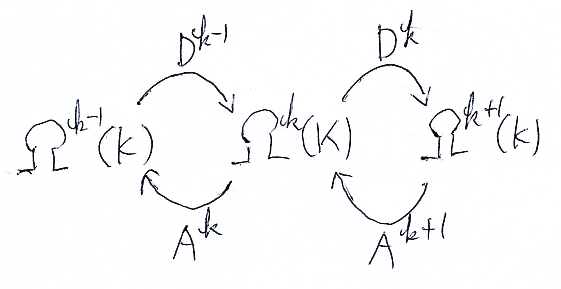
詳しくは「ド・ラーム・コホモロジーとホッジ分解のオモチャ (2/2) // 内積ベクトル空間と随伴線形写像」を参照。
Ak:Ωk(K)→Ωk-1(K) は、余境界作用素の随伴線形写像なので、そのまんま随伴余境界作用素〈adjoint coboundary operator〉、またはベルトラミ作用素〈Beltrami operator〉と呼びます。余境界作用素の系列と、随伴余境界作用素の系列の双方向系列を備えたΩk(K)達を、ここではド・ラーム/ホッジ複体〈de Rham-Hodge complex〉と呼びましょう。通常、これもド・ラーム複体と呼んでしまうのですが、随伴系列があるとホッジ理論(後述)が構成できます。
離散外解析/離散ベクトル解析
今までの話は、基本的には線形代数の議論です。味気ない・色気ないという印象はまぬがれないですね。ここから先では、K = K(G) のド・ラーム/ホッジ複体Ωk(K)に、離散物理的な意味付けを与えます。直感に訴えるカラフル・ヴィヴィッドな描像が得られます。
多様体M上の解析(微積分)を、外微分解析〈exterior differential calculus〉/ベクトル解析〈vector calculus〉と呼びます。外微分解析は微分形式(の場)の微積分、ベクトル解析はベクトル場の微積分です。離散の場合に「微分」を付けるのはさすがに抵抗があるので、「微分形式→形式」「外微分解析→外解析」とします。
まず、離散空間である G = (V, E, T) 上の“ベクトル場”を定義しましょう。Gは、有限無向単純グラフだったので、もともと向き〈direction, orientation〉はないことに注意してください。ベクトル場〈vector field〉は、Gに向きと大きさを与えます。
G上のベクトル場の定義を、インフォーマル・図形的に与えます。Gの無向辺 {A, B} ごとに、その向き〈direction〉を、次のいずれかひとつを実行して与えます。
- AからBに向けた矢印 A→B を描く。
- BからAに向けた矢印 B→A を描く。
- 矢印を描かない。
次に大きさ〈magnitude〉を割り当てます。
- A→B または B→A の矢印には、正の実数を大きさとして割り当てる。
- 矢印を描かなった辺には、大きさ0を割り当てる。
次の絵はGとG上のベクトル場の例です。
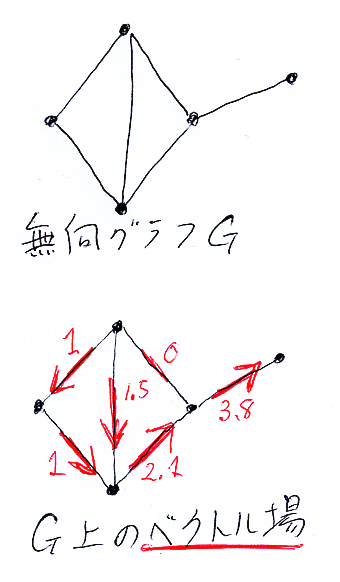
G上のベクトル場をフォーマルに定義すると、1-形式(1-コチェーンともいう)の定義と同じになってしまいます。ベクトル場とは、1-形式に対する別な見方です。ただし、心理的(メンタル)には別物と思っていたほうがいいかも知れません(連続の場合、ベクトル場は1-形式の双対なので)。
連続(多様体)の場合、ベクトル場は多様体上の流れ〈flow〉を誘導します(下の図)。なので、ベクトル場と流れを同義語のように扱う場合もあります。離散の場合も、ベクトル場と流れは、ほぼ同義語として扱います。

離散空間=無向グラフ上の流れは、電気回路〈electric circuit〉や液体パイプ網〈liquid piping network/system〉のモデルと考えるといいでしょう。ベクトル場は、流れの速度や勢いを表します。
離散1-形式を流れと解釈した場合、Ωk(K)の要素は次のような物理的解釈を持ちます。
| 0-形式 ∈Ω0(K) | ポテンシャル または 湧き出し量/吸い込み量 |
| 1-形式 ∈Ω1(K) | 流れ |
| 2-形式 ∈Ω2(K) | 渦源〈うずげん | かげん〉 |
ポテンシャルは、電気回路なら電位です。液体パイプ網なら、頂点にタンクがあるとしてタンクの水量とか位置(高度)かな。湧き出し/吸い込みの量は、頂点が外部と入出力をしているとして、頂点から(電流や液体が)湧き出す/吸い込まれる量です。渦源〈vortex source〉は、三角形の内部にあって、渦を引き起こす源〈みなもと〉。渦源があると、三角形の周囲に循環流〈circulation flow〉が発生します。
離散解析の4つの作用素
2次元のド・ラーム/ホッジ複体では、4つの作用素(線形写像)が出てきます。
- D0:Ω0(K)→Ω1(K) 0次余境界作用素
- D1:Ω1(K)→Ω2(K) 1次余境界作用素
- A2:Ω2(K)→Ω1(K) 2次随伴余境界作用素
- A1:Ω1(K)→Ω0(K) 1次随伴余境界作用素
前節の物理的解釈を念頭に、これらの作用素に別名を与えます。
- grad = D0:Ω0(K)→Ω1(K)
- curl = D1:Ω1(K)→Ω2(K)
- circ = A2:Ω2(K)→Ω1(K)
- div = A1:Ω1(K)→Ω0(K)
gradを勾配〈gradient〉、curlを回転〈curl | rotation〉、circを循環〈circulation〉、divを発散〈divergence〉と呼びます。これらの言葉は、3次元の(普通の)ベクトル解析でお馴染みでしょう。3次元ベクトル解析では、curlとcircの区別がないのですが、それは計算上の差がないからと、違う作用素を同一視しているせいです(よくない)。
gradとcurlの具体的な表示(定義)は既にありますが、circとdivも具体的に表示できます。そのために、無向グラフ上での隣接点〈adjacent point/vertex〉という概念を使います。
- A∈V の隣接点とは、{A, B}∈E となる点B
- {A, B}∈E の隣接点とは、{A, B, C}∈T となる点C
Aの隣接点の全体(からなる集合)をAdja(A)、{A, B}の隣接点の全体をAdja(A, B)と書くことにします*7。隣接点を使って、circ, div は次のように書けます。
$` (circ \,{\bf \sigma})(A, B) \: :=\: \sum_{X\in Adja(A, B)} {\bf \sigma}(A, B, X)`$
$` (div \,\omega)(A) \: :=\: \sum_{X\in Adja(A)} \omega(A, X)`$
この具体的定義と、随伴線形写像としての定義が一致することは計算で確認できます。これらの定義の直感的意味は次のとおりです。
- (circ σ)(A, B) : 辺{A, B}を含む三角形{A, B, X}(の渦源)による循環流の、A→B方向の流量(実数値)を、Xを動かして足し合わせた量。
- (div Ω)(A) : 辺{A, X}の、A→X方向の流量(実数値)を、Xを動かして足し合わせた量。
以下では、1-形式、ベクトル場のことも“流れ”と表現するので気をつけてください。正確に言えば「1-形式/ベクトル場から誘導された流れ」です。
- 流れωが、ポテンシャルfにより ω = grad f = D0(f) と書けるとき、ωを勾配流〈gradient flow〉と呼びます。
- 流れωが、curl ω = D1(ω) = 0 のとき、無回転流〈irrotational flow | curl-free flow〉と呼びます。
- 流れωが、渦源σにより ω = circ σ = A2(σ) と書けるとき、ωを循環流〈circulation flow〉と呼びます。
- 流れωが、div ω = A1(ω) = 0 のとき、無発散流〈divergence-free flow〉と呼びます。
無回転流は、本田圭佑や乾貴士のシュート・テクニックみたいなので、渦無し流れという言葉も使います。無発散流は、外部との入出力(流入と流出)がないので、出入り無し流れとも言うことにします。また、div ω = 0 は物理の非圧縮性流体の連続の方程式(保存則)に類似なので、ωを保存流〈conservative flow〉とも呼びます。
ド・ラーム複体の性質として Dk+1$`\circ`$Dk = 0 なので、次が成立します。
- curl grad f = 0
勾配流 grad f の回転がゼロになるので、ポテンシャルfによる勾配流は必ず渦無しです。
随伴線形写像に関して Ak-1$`\circ`$Ak = 0 が成立するので、
- div circ σ = 0
循環流 circ σ の発散がゼロになるので、渦源σによる循環流は必ず出入り無しの保存流です。
次に述べるホッジ分解は、勾配流、無回転流(渦無し流れ)、循環流、無発散流(出入り無し流れ)のあいだの、もっと精密な関係を与えます。
ホッジ分解
ド・ラーム/ホッジ複体のホッジ分解〈Hodge decompsition〉とは、各次元のコチェーン空間Ωk(K)に対して、直交直和分解を与えるものです。主たる興味は k = 1 のところ、Ω1(K) の分解です*8。ベクトル空間Ω1(K)は1-形式〈1-コチェーン〉の空間ですが、既に述べたように、G上のベクトル場の空間、あるいはG上の流れの空間ともみなせます。
ド・ラーム/ホッジ複体のなかで、Ω1(K)を余域〈終域〉とする作用素が2つ、Ω1(K)を域〈始域〉とする作用素が2つあります。
- grad = D0 : Ω1(K)が余域
- circ = A2 : Ω1(K)が余域
- curl = D1 : Ω1(K)が域
- div = A2 : Ω1(K)が域
Ω1(K)を余域とする作用素ではその像空間を、Ω1(K)を域とする作用素ではその核空間を考えると、Ω1(K)に4つの部分空間が定義できます。それぞれの部分空間の要素の呼び名を記します。(呼び名の整理については、「ド・ラーム・コホモロジーとホッジ分解のオモチャ (2/2) // 多様体から線形代数へ」参照。)
| 要素 | 一般的な呼び名 | 流れモデルの呼び名 |
|---|---|---|
| Ωk(M)の要素 | 1-コチェーン | 流れ |
| Im(grad)の要素 | 1-コバウンダリ | 勾配流 |
| Im(circ)の要素 | 1-随伴コバウンダリ | 循環流 |
| Ker(curl)の要素 | 1-コサイクル | 無回転流(渦無し) |
| Ker(div)の要素 | 1-随伴コサイクル | 無発散流(出入りなし) |
ベクトル空間Ω1(K)の部分空間 Im(grad), Im(circ), Ker(curl), Ker(div) の関係は、次の図のようになります。
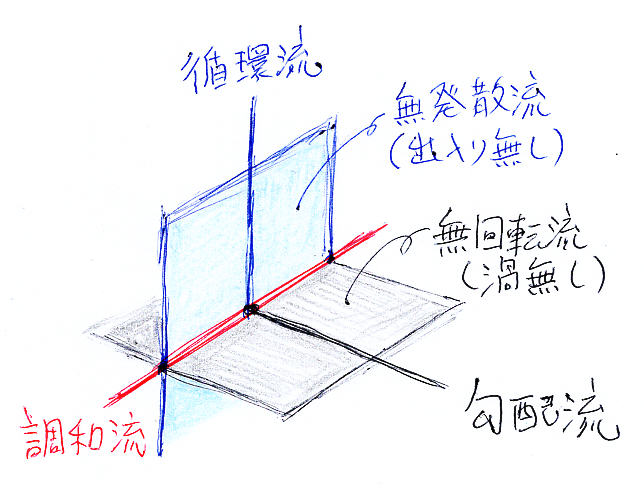
このような部分空間の相互関係を教えてくれるのが、ホッジの定理です。ド・ラーム/ホッジ複体の定義から、「勾配流の空間 ⊆ 無回転流の空間」と「循環流の空間 ⊆ 無発散流の空間」は言えました(前節)が、さらに:
- 勾配流の空間(Im(grad))と無発散流の空間(Ker(div))は直交し、それらの直和はΩ1(K)になる。
- 循環流の空間(Im(circ))と無回転流の空間(Ker(curl))は直交し、それらの直和はΩ1(K)になる。
- 無回転流の空間(Ker(curl))と無発散流の空間(Ker(div))の共通部分(Ker(culr)∩Ker(div))を調和流〈harmonic flow〉の空間と呼ぶ(これは定義)。
- 勾配流の空間(Im(grad))と循環流の空間(Im(circ))と調和流の空間(Ker(culr)∩Ker(div))は互いに直行し、それらの直和はΩ1(K)になる。
次の3つの直交直和分解がホッジ分解です。
- Ω1(K) = Im(grad) $`\oplus`$⊥ Ker(div)
- Ω1(K) = Im(circ) $`\oplus`$⊥ Ker(curl)
- Ω1(K) = Im(grad) $`\oplus`$⊥ Im(circ) $`\oplus`$⊥ (Ker(curl)∩Ker(div))
ド・ラーム/ホッジ複体の対するホッジ分解定理は、純粋に代数的に証明できます。次を参照してください。
調和流の空間は、Ker(curl)∩Ker(div) として定義しましたが、ラプラシアン(という作用素)の核空間としても定義できます。それについては:
ホッジ分解のランキング問題への応用(見出しだけ)
... TBD ...
*1:ここで登場する単体複体は、グラフの2-クリーク複体〈2-clique complex〉と呼ばれるものです。
*2:k-単体と呼んでもいいのですが、ここでの定義では、非退化な単体しか考えてないのでセルと呼ぶことにしました。
*3:「混ぜてカリー化」は、どう考えても料理の手法。
*4:Ω-1(K) := O = ゼロ空間、Ω3(K) := O、D-1:Ω-1(K)→Ω0(K)、D2:Ω2(K)→Ω3(K) と定義すると、次数付けの辻褄は合います。D-1の(-1)は逆写像じゃなくて、単なる番号です。まー、次数付けの整合性は気にするほどのことではないでしょう。
*5:ポテンシャルは、スカラー体や1次元ベクトル空間に値をとるというより、1次元アフィン空間に値をとるので、原点の選び方は自由です。
*6:画像: https://en.wikipedia.org/wiki/Vector_field#/media/File:VectorField.svg より
{kind=link}
*7:AdjでなくAdjaとしたのは、adjointやadjunctionと誤解されないようにです。
*8:k = 1 のホッジ分解をヘルムホルツ分解〈Helmholtz decomposition〉とも呼びます。