リスト処理の高階関数にfoldrとfoldlがあります。その引数仕様は次のように書けます。
- foldr(list, fun, val)
- foldl(list, fun, val)
ここで、listはリスト、funは2引数の関数、valは“初期値”となる値です。型をちゃんと書くと次のようにうるさいことになります。
- foldr(list : List<X>, fun : Fun<X, Y -> Y>, val : Y)
- foldl(list : List<X>, fun : Fun<X, Y -> Y>, val : Y)
うるさいので、型については考えないことにします。
foldr, foldlってなーに?
先に、foldrについて説明します。rは右(right)の意味です。右から(左に向かって)畳んでいく計算です。具体的なリストとして [2, 4, 1] を取りましょう。リストを二分木(バイナリーツリー)で表現すると次のように描けます。
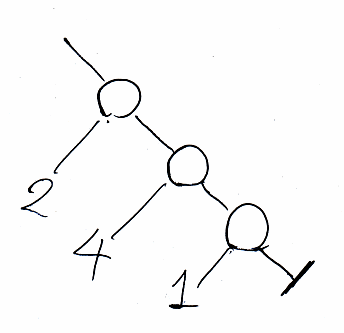
Lispの用語法を使えば、白丸はconsセル、右下の行き止まり記号(リストの終端子)はnilです。
2引数の関数funとしては足し算を行う関数(二項演算子)、“初期値”となる値valは10としましょう。つまり、次を計算します。
- foldr([2, 4, 1], function(x, y){return x + y}, 10)
foldrを計算するには、二分木で描いたリストのconsセル(白丸)に関数funを書き込み、nil(終端子)を初期値で置き換えます。今の場合、関数funは足し算なのでプラス記号を使いました。nilの位置には10が入ります。
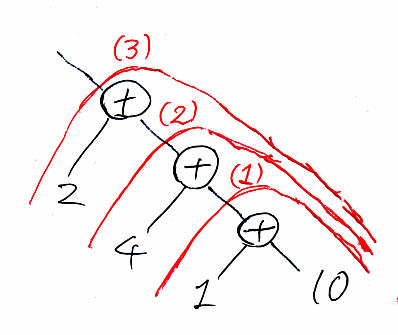
赤で描いている (1), (2), (3) は計算の順番です。つまり、次のように計算が進みます。
- 10 + 1 = 11
- 11 + 4 = 15
- 15 + 2 = 17 (答え)
foldlは、foldrの逆順なんですが、対称性が分かるように絵のレイアウトを少し変えてみます。
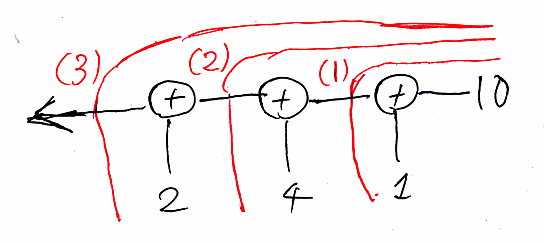
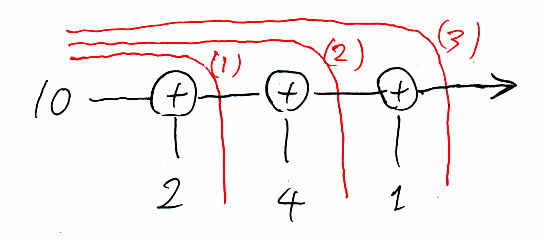
foldr(上)なら右から左、foldl(下)なら左から右です。足し算では、どっちでも結果は同じですが、2引数関数funの選び方によっては、foldrとfoldlで結果が変わります。
foldr, foldlってすごいの?
foldr/foldlを使うと、明示的な再帰を書かなくても再帰処理ができるので便利です。リストを「右から」または「左から」たどりながら、それまでの計算結果(累積値)も利用して計算を進めることができます。
foldr/foldlの本質は、空間的に展開されたデータ構造に対して、処理の時間順序を与えることです。リストの場合はデータ構造が線形(リニア)なので、「右から左」と「左から右」の二つの方向で順次処理が可能です。それで、rとlがあるのです。
リスト以外のデータ構造(例えば、二分木とは限らない一般的なツリー)に対してもfoldを定義可能です。シーケンシャルな時間順序をどのように与えるかによりfold関数の定義は変わります。並列処理を前提にするなら、シーケンシャルな時間ではなくてパラレルな時間を考えることになります。
冒頭で、「うるさいので、型については考えないこと」にしたのですが、foldの型付けを厳密に考えると面白い話に発展します。「キュリアの格上げによる総称の解釈」で引用した論文"Parametric Datatype-Genericity"では、fold関数を高階自然変換(higher-order natural transformation)の典型例として取り扱っています。