ここ最近の本ブログのテーマは「カリー/ハワード/ランベック対応」です。最近の記事がすべてカリー/ハワード/ランベック対応に関係するわけではありませんが、9月の記事「関数の構成法 (カリー/ハワード/ランベック対応も少し)」あたりから、カリー/ハワード/ランベック対応についてまた考える機会が増えました。
以前からの悩みのタネなんですが、「カリー/ハワード/ランベック対応とハイティング/ド・モルガン圏」で書いたこと:
この綺麗な対応がなかなか伝わらないようです。対応が見えにくくなっている大きな原因は、構造が綺麗に対応していても、言葉や記号は対応してないことです。論理/型理論/圏論の三者において、まったく違った呼び名・書き方・言い回しが使われています。
...[snip]...
表層的な呼び名・書き方・言い回しの違いに惑わされて、概念・構造の同型性が見えにくくなっているケースが多いようです。
この問題をなんとかしたい。切実になんとかしたい。
呼び名・書き方・言い回しの違いに惑わされるって、ほんとにモッタイナイなーと思います。どうでもいいことに邪魔されて綺麗な対応が見えないって、それは残念過ぎる。
呼び名・書き方・言い回しに、どうしてこんなにも無意味・無駄なバリエーションがあるのか? それは歴史・伝統・習慣のせいです。歴史・伝統・習慣は尊重されて然るべきものでしょうが、あまりに弊害が大きいなら考え直してもいいのではないでしょうか。$`
\newcommand{\mrm}[1]{ \mathrm{#1} }
%\newcommand{\mbf}[1]{\mathbf{#1}}
%\newcommand{\msf}[1]{\mathsf{#1}}
%\newcommand{\mbb}[1]{\mathbb{#1}}
%\newcommand{\hyp}{\text{-} }
\newcommand{\In}{ \text{ in } }
%\newcommand{\twoto}{\Rightarrow }
%\newcommand{\ot}{\leftarrow}
\newcommand{\Imp}{\Rightarrow }
%%
\require{color} % Using
%\newcommand{\hinfer}{ \rightrightarrows }% horizontal meta rule (infer)
\newcommand{\vinfer}{ \downdownarrows }% vertical meta rule (infer)
%\newcommand{\Rule}[1]{ \textcolor{orange}{\underline{\text{#1}}\: } } % rule name
%%
%\newcommand{\NN}[1]{ \textcolor{orange}{\text{#1}} } % New Name
%\newcommand{\NX}[1]{ \textcolor{orange}{#1} } % New EXpression
\newcommand{\T}[1]{\text{#1} }
`$
内容:
導出系
カリー/ハワード/ランベック対応が訴えているメッセージは、「型理論と論理と圏論は、同じものを扱い、同じことをやっているんだよ」ということです。しかし、各分野の歴史・伝統・習慣のせいで、使っている呼び名・書き方・言い回しはまったく違います。この記事でやりたいことは、各分野ごとの無意味・無駄なバリエーションを削り落として、呼び名・書き方・言い回しを揃えることです。
型理論と論理における次の4つの calculus を考えます。
| 型理論 | 論理 |
|---|---|
| 通常関数計算 | 自然演繹 |
| 関数プロファイル計算 | シーケント計算 |
calculus とは何らかの計算システムのことですが、微積分のことだと思う人もいるでしょう。「演繹系〈deduction system〉」(以下の過去記事参照)という適切な言葉があるのですが、「演繹」が論理の言葉なので、論理の計算システムと誤解されかねません。
ここでは、演繹系を導出系〈derivation system〉と呼んでおきます。つまらないリネームですが、つまらないこと(言葉の僅かな違い)に影響を受ける人もいるので*1。
「4つの calculus」は「4つの導出系」と言い換えられます。「4つの計算系」、「4つの演繹系」、「4つの証明系」と言っても同じです -- こういうのが無駄なバリエーションなわけですけどね(苦笑)。
4つの導出系の概要は:
- 通常関数計算: 型付きラムダ計算の計算法を導出系に仕立てたものです。ごく常識的な関数の計算を定式化しています。
- 関数プロファイル計算: 関数の入力型〈引数型〉と出力型〈戻り値型〉の仕様がプロファイルです。関数プロファイル計算は、関数のプロファイルを計算するための導出系です。
- 自然演繹: 前提〈仮定 | 仮説〉の論理式から結論の論理式を導出するための導出系です。
- シーケント計算: 定理の前提と結論の記述(ステートメントともいう)がシーケントです。シーケント計算は、定理のシーケントを計算するための導出系です。
以上の説明から、次のような言葉〈呼び名〉の対応があることは察しがつくでしょう。
| 型理論 | 論理 |
|---|---|
| 計算 | 証明 |
| 関数 | 定理 |
| プロファイル | シーケント |
| 引数型 | 前提命題 |
| 戻り値型 | 結論命題 |
「命題」「型」という曖昧多義語(「命題」と「型」の曖昧性を図示)を使いますが、曖昧性解決のためには、語尾に「項」「実体」を付けます。
- 命題項: 論理式のこと
- 命題実体: 述語のこと
- 型項: 型を表現する構文的対象物〈項 | 式〉
- 型実体: 型の意味論的対象物(意味論により解釈が異なるが、例えば集合)
上の対応表のような相互翻訳を提示すると、各分野ごとの用語が持つ語感、ニュアンス、連想などを持ち出して、「意味が違う、翻訳になってない」と言う人がいますが、それを言い出すと翻訳は不可能です。多少の意味的ズレとか気持ち・感情の問題には目をつぶってください。
基本導出ステップ、導出ルール
導出系には基本導出ステップ〈primitive derivation step〉が決まっています。基本導出ステップの適用法を書き下したものを導出ルール〈derivation rule〉と呼ぶことにします。論理では推論ルール〈inference rule | 推論規則〉と呼びます。が、「導出」、「証明」、「推論」、「演繹」などの混用・併用が無駄なバリエーションなので、「推論」という言葉はテクニカルタームとしては使いません。
導出ルールは一律に次の形で書くことにします。
~~の☓☓ルール ルール名 ◯◯のリスト 下向き矢印 基本☓☓ステップ ステップ名 ◯◯
例を挙げます。
まず、~~、◯◯、☓☓ を具体化すると:
通常関数計算の計算ルール ルール名 型項のリスト 下向き矢印 基本計算ステップ ステップ名 型項
次に、ルール名、型項のリスト、下向き矢印、ステップ名、型項 を具体化します。LaTeX(MathJax)で書きます。
\text{通常関数計算の計算ルール }\T{評価}\\
\:\\
\quad ([A, B], A)\\
\downarrow \T{基本計算ステップ }\mrm{ev}\\
\quad B
`$
ここで、$`[A, B]`$ は関数空間型〈写像空間型 | 指数型〉を表します。$`\mrm{Map}(A, B)`$ とか書いてもかまいません -- お好きな記法でどうぞ。
こういう書き方は簡略化されるものなので、簡略化の過程も述べておきます。日本語の説明的な語句は省略します。すると:
\T{評価}\\
\:\\
\quad ([A, B], A)\\
\downarrow \mrm{ev}\\
\quad B
`$
ルール名とステップ名を同じ名前に揃えます。
\mrm{ev}\\
\:\\
\quad ([A, B], A)\\
\downarrow \mrm{ev}\\
\quad B
`$
同じ名前を二度書くのは冗長なので、ステップ名を省略します。
\mrm{ev}\\
\:\\
\quad ([A, B], A)\\
\downarrow \\
\quad B
`$
書くスペースを節約するために、縦矢印を横矢印に変えて、改行も入れないようにします。
\mrm{ev} : ([A, B], A) \to B
`$
んっ、アレ? 単なる(多変数関数の)プロファイル記述では? -- そうです。そうなんです。通常関数計算の計算ルールは、基本となる関数〈primitive function〉のプロファイル記述にほかなりません。書き方が違うだけです。
論理の自然演繹ならなんか違うんじゃないのか? いえっ、違いません。
まず、~~、◯◯、☓☓ を具体化すると:
自然演繹の証明ルール ルール名 命題項のリスト 下向き矢印 基本証明ステップ ステップ名 命題項
次に、ルール名、命題項のリスト、下向き矢印、ステップ名、命題項 を具体化します。LaTeX(MathJax)で書きます。
\text{自然演繹の証明ルール }\T{モーダスポネンス}\\
\:\\
\quad ([P, Q], P)\\
\downarrow \T{基本証明ステップ }\mrm{MP}\\
\quad Q
`$
論理の習慣として、$`[P, Q]`$ は $`P \Imp Q`$ と書きます。日本語の説明的な語句は省略します。すると:
\T{モーダスポネンス}\\
\:\\
\quad (P \Imp Q, P)\\
\downarrow \mrm{MP}\\
\quad Q
`$
ルール名とステップ名を同じ名前に揃えます。
\mrm{MP}\\
\:\\
\quad (P \Imp Q, P)\\
\downarrow \mrm{MP}\\
\quad Q
`$
同じ名前を二度書くのは冗長なので、ステップ名を省略します。
\mrm{MP}\\
\:\\
\quad (P \Imp Q, P)\\
\downarrow \\
\quad Q
`$
書くスペースを節約するために、縦矢印を横矢印に変えて、改行も入れないようにします。
\mrm{MP} : (P \Imp Q, P) \to Q
`$
通常関数計算の評価の場合と何も変わりません。違うような気がするとしたら、それは「気がする」だけです。あるいは抽象化が足りません。通常関数計算の評価と自然演繹のモーダスポネンスは、抽象化したレベルでは同じなのです。圏論は、よく出来た抽象化の枠組み(例えばデカルト閉圏)を提供してくれます。
導出ルールの実例もっと
前節の導出ルールの一般的パターンを再掲すると:
~~の☓☓ルール ルール名 ◯◯のリスト 下向き矢印 基本☓☓ステップ ステップ名 ◯◯
ここで、「〇〇のリスト」と書いてますが、実際のリストの構文も実にさまざまです。囲み記号(括弧記号)が色々あるし、囲み記号を省略することもあります。区切り記号も色々あります。目に見えない空白や改行を区切り記号に使うことも多くあります。そういうどうでもいい書き方の違いをすべて無視できる能力が重要になります。
ここでは、リストの囲み記号は丸括弧、区切り記号はカンマです。囲み記号は省略することもありますが、安易な省略は避けます(誤解・誤認のもとなので)。
通常関数計算と自然演繹の、対応する導出ルールを幾つか挙げます。導出ルール上段のリスト囲み記号である丸括弧は省略します。
\T{通常関数計算の計算ルール }\T{第一射影}\\
\:\\
\quad A \times B\\
\downarrow \pi_1\\
\quad A
`$
これは、横向きで書けば $`\pi_1 : A\times B \to A`$ です。対応する自然演繹の導出ルール〈証明ルール〉は:
\T{自然演繹の証明ルール }\T{連言除去・左抽出}\\
\:\\
\quad P \land Q\\
\downarrow \T{conj-E left}\\
\quad P
`$
ペアを作る操作を二変数関数として記述すると:
\T{通常関数計算の計算ルール }\T{ペア構成}\\
\:\\
\quad A \, ,\; B\\
\downarrow \mrm{pair}\\
\quad A\times B
`$
対応する自然演繹の導出ルール〈証明ルール〉は:
\T{自然演繹の証明ルール }\T{連言導入}\\
\:\\
\quad P \, ,\; Q\\
\downarrow \T{conj-I}\\
\quad P\land Q
`$
データとしてのペアを作るのと似てますが、関数のペア(デカルト・ペア)を作る操作をプロファイル計算の導出ルール〈計算ルール〉として書くと次のようです。
\T{プロファイル計算の計算ルール }\T{関数のペア構成}\\
\:\\
\quad C \to A \, ,\; C \to B\\
\vinfer \mrm{Pair}\\
\quad C \to A\times B
`$
プロファイル計算であることを明示するために、下向き矢印を二本矢印にしています。同じことをシーケント計算の導出ルール〈証明ルール〉として書くと:
\T{シーケント計算の証明ルール }\T{定理の連言構成}\\
\:\\
\quad R \to P \, ,\; X \to Q\\
\vinfer \mrm{Conj}\\
\quad R \to P\land Q
`$
関数をカリー化する操作をプロファイル計算の導出ルール〈計算ルール〉として書くと次のようです。
\T{プロファイル計算の計算ルール }\T{関数のカリー化}\\
\:\\
\quad A\times B \to C\\
\vinfer \mrm{Curry}\\
\quad A \to [B, C]
`$
同じことをシーケント計算の導出ルール〈証明ルール〉として書くと:
\T{シーケント計算の証明ルール }\T{含意導入}\\
\:\\
\quad P\land Q \to R\\
\vinfer \T{Imp-I}\\
\quad P \to Q \Imp R
`$
パターンに従うように、呼び名と書き方を揃えると、ほんとに同じだと実感できるでしょう。個別ケースごとに、伝統・習慣による別々な/バラバラな呼び名と書き方はもちろんあります。それらを覚えたり慣れたりするのは、共通パターンを認識した後ならけっこう楽です。
パターンとプレースホルダー
導出ルールの一般的パターンを再々掲します。
~~の☓☓ルール ルール名 ◯◯のリスト 下向き矢印 基本☓☓ステップ ステップ名 ◯◯
ここに出てくるプレースホルダーは、次の“値”で埋めて具体化します。
| プレースホルダー | 値 |
|---|---|
| ~~ | 通常関数計算、関数プロファイル計算 ; 自然演繹、シーケント計算 |
| ☓☓ | 計算 ; 証明 |
| ◯◯ | 型項、関数プロファイル ; 命題項、シーケント |
セミコロンの左が型理論、右が論理の場合の“値”です。例えば、~~ の値に「シーケント計算」を選ぶと、☓☓ は「証明」、◯◯ は「シーケント」となるので、具体化は次のようです。
シーケント計算の証明ルール ルール名 シーケントのリスト 下向き矢印 基本証明ステップ ステップ名 シーケント
ルール名やステップ名は、伝統・習慣に従うとして、また別な具体化の例を挙げれば:
\T{シーケント計算の証明ルール }\T{切断}\\
\:\\
\quad P\to Q \, ,\; Q \to R\\
\vinfer \mrm{Cut}\\
\quad P \to R
`$
これは、関数プロファイル計算なら関数の結合〈composition〉に相当します。「論理では、なんで切断〈Cut〉と呼ぶんだ?」は、それこそ伝統・習慣の問題なので僕は知りません。どうしても気になるなら、語源・由来はご自分で調べてください。
導出ツリー図
導出ルールでは、上段に前提を書いて、下段に結論を書きます。この形を何段も積み重ねると、ツリーの形になります。ツリーのノードの部分が基本導出ステップで、エッジに型項/命題項がラベルされます。テキストでツリーの形状を表現するのは難しいです。下の図は手描きのツリーで、過去記事「球体集合達の圏の構文表示 2/2」からの引用です。
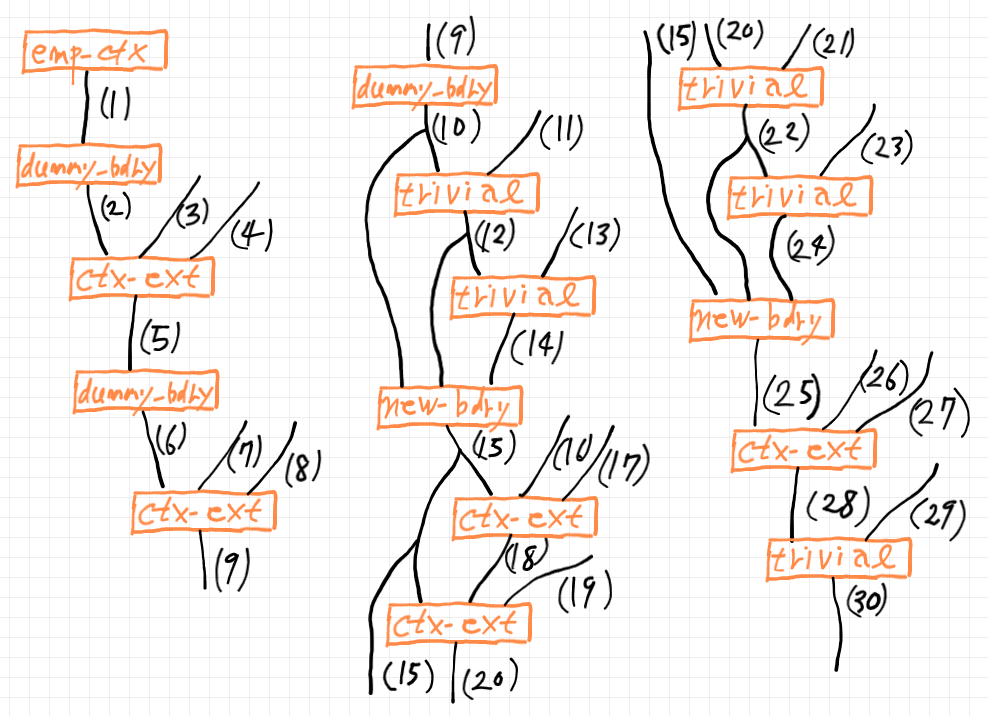
基本導出ステップの組み合わせを視覚化した図を導出ツリー図〈derivation tree figure〉と呼びましょう。論理の伝統的用語では証明図〈proof figure〉です。
論理では、頑張ってテキストでツリーを描く技法があり、LaTeXマクロとしても提供されています。しかし、画像検索で証明図を探しても意外と出てこない。LaTeXマクロを使っても描くのが大変だから、そんなに気軽に作れるものではないからでしょう*2。以下の図は、Sequents and Trees という本の Gentzen’s Sequent Calculus LK の章にある図のようです(たまたま見つけたもの)。
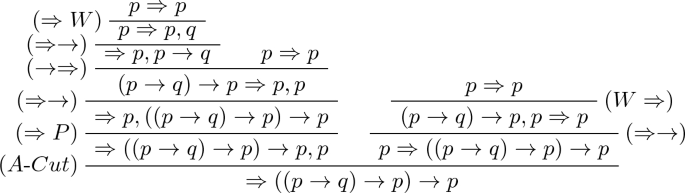
$`\to, \Imp`$ の使い方がこの記事とは逆で、$`\to`$ が含意の演算子記号で、$`\Imp`$ がシーケントの左右を区切る記号(エンテイルメント記号)です。さらには、シーケントの右辺のカンマは連言〈論理OR〉の意味を持つという分かりにくい習慣(以下の過去記事参照)を採用しているので、解釈は面倒かも知れません。しかし、ツリーの形状は読み取れるでしょう。
通常関数計算における導出ツリー図は、関数の組み合わせ方をツリーに描いたもので、事実上、ラムダ項〈ラムダ式〉の構文解析ツリーです。
あまり指摘されないのですが、大事な注意として、通常関数計算/自然演繹の導出ツリー図では、計算や証明の過程を完全に記述することは出来ません。カリー化/含意導入などの操作は、描かれているツリー図を描き換える操作なので、アニメーション(図の時間的変更、ムービー)が必要なのです。静的な導出ツリー図ではアニメーション〈ムービー〉は無理です。アニメーションのヒントを書き添えることでお茶を濁しています。関数プロファイル計算/シーケント計算では、計算や証明の過程を、静的な図で完全に記述できます。
そしてそれから
この記事では、共通化した呼び名・書き方に対する、各分野ごとの呼び名・書き方の紹介はあまりしていません。次の過去記事が参考になるかも知れません。
各分野ごとの呼び名・書き方は、自分の理解のためにはどうでもいい(むしろ邪魔になる)ことですが、コミュニケーションの道具としては必要です。標準語がない国を旅行するようなもので、「郷に入っては郷に従え」で、その地域ごとの言葉を知る必要があります。
もうひとつ省略した話題に、名前付きのプロファイル/シーケントがあります。例えば、関数のプロファイル $`(A, B)\to C`$ に名前を付けると、$`(x:A, y:B)\to C`$ のようになります。導出ツリー図の結論をテキストに書き下すときは名前付きのプロファイル/シーケントが必要です。名前の扱いは意外と面倒で難しいのですが、実用上は避けて通れません。