「球体集合達の圏の構文表示 1/2」の続きです。この機会に、型理論的な形式的体系と構文的データについて詳しく説明します。一方、形式的体系の構文圏と圏同値の話は、概要を急ぎ足で述べるだけになってしまいました -- いずれ補足する機会もあるでしょう。$`\newcommand{\mrm}[1]{ \mathrm{#1} }
\newcommand{\cat}[1]{ \mathcal{#1} }
\newcommand{\In}{\text{ in }}
\newcommand{\id}{ \mathrm{id} } % use
\newcommand{\twoto}{ \Rightarrow } % use
%\newcommand{\op}{ \mathrm{op} }
%\newcommand{\Imp}{\Rightarrow}
%\newcommand{\hyp}{\text{-} }
\newcommand{\H}[1]{ {#1}\text{-} }
\newcommand{\Glob}{\mathsf{Glob} }
\newcommand{\NM}{\boldsymbol{\Omega}}
\newcommand{\AN}[1]{\mathsf{#1}} % Actual Name
%%
\newcommand{\LL}{\langle} % List Left
\newcommand{\LR}{\rangle} % List Right
%%
\require{color} % Using
\newcommand{\NN}[1]{ \textcolor{orange}{\text{#1}} } % New Name
\newcommand{\NX}[1]{ \textcolor{orange}{#1} } % New EXpression
\newcommand{\T}[1]{\text{#1} }
%%
\newcommand{\ckw}[1]{ \:{\bf \text{ #1} } } % classifier keyword
\newcommand{\hinfer}{ \rightrightarrows }% horizontal meta rule (infer)
\newcommand{\vinfer}{ \downdownarrows }% vertical meta rule (infer)
\newcommand{\Emp}{ \langle\rangle }
\newcommand{\Rule}[1]{ \textcolor{orange}{\underline{\text{#1}}\: } } % rule name
\newcommand{\num}[1]{\quad \text{--}(#1) } % numbering
`$
内容:
ハブ記事:
形式的体系
形式的体系〈formal system〉とは、形式言語理論、論理、型理論などの構文論を展開するための構造です。集合と関数から組み立てられる構造なので、構文{論}?的だからといって(一般的な数学的構造と比べて)特殊なわけではないです。が、おそらく、具体的・有限的に構成可能な構造を期待して「構文{論}?的」と言うのでしょう。
ここで構成する形式的体系は $`\Glob`$ とします。$`\Glob`$ で使う名前〈ラベル | 識別子〉達の無限集合を $`\NM`$ とします。無限集合 $`\NM`$ の要素を「名前」と呼ぶだけのことで、名前が文字列である必要性はありません。無限集合なら何でもいいので $`\NM := {\bf N}`$ とか $`\NM := {\bf Q}`$ と置けばいいです。可算無限より大きな $`{\bf R}`$ や $`{\bf R}^2`$ を $`\NM`$ にとってもいいです。別に何でもいいです。選んで固定します。
リストの囲み記号には山形括弧を使います。これは、記法を「最近の型理論: 具体的・構文的なコンテキスト」と揃えただけで特に意味はありません。リストの最後に項目を追加することをリストの拡張〈extension | 拡大〉と呼び、拡張の演算子記号にナカグロ '$`\cdot`$' を使います。
$`\quad \LL x_1, \cdots, x_n\LR \cdot y = \LL x_1, \cdots, x_n , y\LR`$
形式的体系を構成する構文的データは、ほとんどが、リスト(空リスト、単一成分のリスト、ペアやトリプルも含む)にタグを前置した形です。タグにアットマーク始まりの名前を使うことにします。例えば、コンテキスト(後述)はリストですが、そのリストがコンテキストであることを識別するために $`\T{@ctx}`$ というタグを前置します*1。
$`\quad \T{@ctx}\LL d_1, \cdots, d_n\LR`$
コンテキストの項目〈成分〉は宣言であり、宣言はトリプルですが、宣言であることを識別するためにタグ $`\T{@decl}`$ を付けるなら:
$`\quad \T{@ctx}\LL \T{@decl}\LL x_1, k_1, t_1\LR, \cdots, \T{@decl}\LL x_n, k_n, t_n\LR\LR`$
このようにして構文的データを定義していくと、機械的処理には向いています。が、人間が読むには煩雑となるので、実際にはタグを省略します。代わりに(必要なら)、囲み記号や区切り記号を変えることで構文的役割り〈syntactic role〉を区別します。
構文的役割りは、言語学の用語で「統語範疇」とか「文法範疇」とか呼びますが、"syntactic category" が「構文圏」と丸かぶりなので、そういう言葉は使いません。「非終端記号」(形式言語理論の用語)という言い方もしません。
構文的データ構造の概要
形式的体系 $`\Glob`$ を組み立てるために必要なデータ領域/データ構造を列挙しましょう。用語と記法は、フィンスター/ミムラム論文をベースにしていますが、都合により変更はしています。
- 名前 : 集合 $`\NM`$ の要素。ラテン文字 $`x, y`$ (これは $`\NM`$ 上を走る変数)などで表す。
- 型コンテキスト : 型宣言のリスト。ギリシャ文字大文字 $`\Gamma, \Delta`$ などで表す。
- 型宣言 : 名前と次元(整数値)と境界項(後述)のトリプル。型宣言トリプル $`\T{@decl}\LL x, k, A\LR`$ を $`(x :^k A)`$ と書く。
- 項 : 詳細は後述。境界項とインスタンス項に分類される。
- 境界項は、ラテン文字大文字 $`A, B`$ などで表す。
- インスタンス項は、ラテン文字小文字 $`t, u`$ などで表す。
- 代入 : 詳細は後述。$`\sigma`$ をインスタンス項のリストとして、$`\Gamma := \sigma`$ と書く。
- 型判断: 詳細は後述。型コンテキスト、境界項、型宣言、インスタンス項、代入の構文的正当性を表現する構文的データ。次のいずれかの形で書く。
- $`\Vdash \Gamma \ckw{ctx}`$
- $`\Gamma \vdash A \ckw{bdry}`$
- $`\Gamma \vdash (t :^k A) \ckw{inst}`$
- $`\Delta \vdash (\Gamma := \sigma) \ckw{subst}`$
- 型推論規則 : 詳細は後述。
- 型導出ツリー :詳細は後述。
形式的体系 $`\Glob`$ は、型理論のマナーに従って構成される形式的体系になります。型理論的体系〈type-theoretic system〉ですね。型理論的体系を単に“型理論”、あるいは“型システム”と呼ぶこともあります。用語の語頭に付いてる「型」はしばしば省略します。例えば、型コンテキストは単にコンテキストとも呼びます。
名前の集合 $`\NM`$ と自然数の集合 $`{\bf N}`$ (ダミー次元に $`-1`$ も使うけど)は事前に与えられているとして($`\NM = {\bf N}`$ かも知れない)、具体的に実行可能な相互再帰的な手順で、構文的役割り〈syntactic role〉ごとの集合が定義できます。構文的役割りごとの集合はたいてい無限集合ですが、その要素である構文的データは、有限的で機械的な手順で作り出すことができます。そのことが「構文的」と呼ばれる所以でしょう。
「項」と呼ばれる構文的データには注意が必要です。多くの型理論では、項は型項〈type term〉とインスタンス項 〈instance term〉に分類されます。なぜか、型項は「型」と省略され、インスタンス項は「項」と省略されます。
| 項の種類 | 略称 |
|---|---|
| 型項 | 型 |
| インスタンス項 | 項 |
この省略はバランスが悪く弊害もあるので、ここでは採用しません。また、「型項」ではなくて「境界項」という呼び名にします。そのほうが、今の事例にはふさわしいからです。境界項の幾何的な意味はn次元の球面(ダミーの(-1)次元球面、ニ点、円周、通常の球面など)です。
「型」という言葉を辞書的意味で狭く固定的に考える必要はなくて、インスタンスを特徴づける情報、あるいは、インスタンスの所在地や所属組織の情報であると考えましょう。球体集合の場合は、インスタンス -- すなわちセルを特徴づけ、所在を明らかにする情報はセルの境界(球面)によって与えられます。よって、セルを表すインスタンス項〈instance term〉に対して、所在を表す境界項〈boundary term〉となります。
通常、項(と呼ばれる記号的表現)には代数演算の演算記号〈関数記号〉が含まれます。例えば算術式〈算術項〉なら、足し算記号 '$`+`$' と掛け算記号 '$`\times`$' とかです。しかし、球体集合には代数演算が何も定義されてないので、インスタンス項〈セル項〉に演算記号がなく、単に名前だけです。つまり、今回の事例 $`\Glob`$ では、インスタンス項の集合と名前の集合は同じです。データとしては同じでも構文的役割りは違うので、インスタンス項としての役割りを担う名前は「インスタンス項」と呼びます。
構文的データ達を相互再帰的に定義する方法として、BNF〈バッカス/ナウア形式 | Backus-Naur form〉(「コンピュータによる言語処理の常識」参照)のようなメタ記法もありますが、ここでは自然言語(の散文)もまじえて半形式的に定義していきます(次節から)。
構文的データの定義
正式な構文的データは、先頭にタグが付いたリストだとします。が、実際には略記を使います。タグが構文的役割りを表します。次の約束をします。
- タグが $`\T{@foo-bar}`$ である構文的データ達の集合は $`{\bf FooBar}`$ と命名する。
- 定義した構文的データが整形式〈well-formed〉(構文的に正しい)とは限らない。整形式な構文的データ達の集合は $`{\bf wfFooBar}`$ のように、先頭に $`{\bf wf}`$ を付けた名前にする。
- 「整形式〈well-formed〉」と「構文的に正当〈syntactically correct〉」は同義語として使う。
以下に箇条書きで構文的データの定義を書きます。
- 名前〈name〉とは、集合 $`\NM`$ の要素のこと。名前変数は $`x, y`$ など。整数〈integer〉とは、集合 $`{\bf Z}`$ の要素のこと。整数変数は $`k, l`$ など。名前と整数にはタグが付かない。
- 宣言〈declaration〉とは、$`\T{@decl}\LL x, k, A\LR`$ のパターンのデータ。ここで、$`A`$ は境界項(後述)。
- コンテキスト〈context〉とは、
$`\T{@ctx}\LL \T{@decl}\LL x_1, k_1, A_1\LR, \cdots, \T{@decl}\LL x_n, k_n, A_n\LR \LR`$
のパターンのデータ。コンテキスト変数は $`\Gamma, \Delta`$ 。 - 境界項〈boundary term〉とは、$`\T{@bdry}\Emp`$ または $`\T{@bdry}\LL t, u, k, B\LR`$ のパターンのデータ。ここで、$`t, u`$ はインスタンス項(後述)、$`B`$ は境界項(再帰的な定義)。
- インスタンス項〈instance term〉とは、$`\T{@inst}\LL x \LR`$ のパターンのデータ。
- コンテキストの判断〈judgement for context〉とは、$`\T{@ctx-judge}\LL \Gamma \LR`$ のパターンのデータ。
- 境界付きインスタンス項〈instance term with boundary〉とは、
$`\T{@inst-bdry}\LL t, k, A\LR`$のパターンのデータ。 - 境界付きインスタンス項の判断〈judgement for instance term with boundary〉とは、$`\T{@inst-bdry-judge}\LL \Gamma, \T{inst-bdry}\LL t, k, A\LR \LR`$ のパターンのデータ。
- 境界項の判断〈judgement for boundary term〉は、$`\T{@bdry-judge}\LL \Gamma, A\LR`$ のパターンのデータ。
- 代入〈substitution〉とは、$`\T{@subst}\LL \Gamma, \sigma \LR`$ のパターンのデータ。ここで、$`\sigma`$ はインスタンス項のリスト、つまり集合 $`\mrm{List}({\bf Inst})`$ の要素。
- 代入の判断〈judgement for substitution〉とは、$`\T{@subst-judge}\LL \Delta, \T{@subst}\LL \Gamma, \sigma\LR \LR`$ のパターンのデータ。
定義・記述のために(メタレベルで)使用する/した変数をまとめておくと:
- $`x, y\in \NM,\; k, l\in {\bf Z}`$
- $`t, u \in {\bf Inst}`$
- $`A, B \in {\bf Bdry}`$
- $`\Gamma, \Delta \in {\bf Ctx}`$
- $`\sigma, \rho \in \mrm{List}({\bf Inst})`$
次の略記を採用します。矢印記号の使用法の方針は「矢印記号の使用法と読み方 2024」参照。
- 宣言 $`\T{@decl}\LL x, k, A\LR`$ は、 $`(x :^k A)`$ と略記。
- コンテキスト $`\T{@ctx}\LL \cdots \LR`$ は、単なるリストとして書く(タグ省略)。
- 境界項 $`\T{@bdry}\Emp`$ は、 $`*`$ と略記、境界項 $`\T{@bdry}\LL t, u, k, B\LR`$ は、 $`(t \to u :^k B)`$ と略記。
- インスタンス項 $`\T{@inst}\LL x \LR`$ は、単に $`x`$ と書く(タグ省略)。
- コンテキストの判断 $`\T{@ctx-judge}\LL \Gamma \LR`$ は、 $`\Vdash \Gamma \ckw{ctx}`$ と略記。
- 境界付きインスタンス項 $`\T{@inst-bdry}\LL t, k, A\LR`$ は、 $`(t :^k A)`$ と略記。
- 境界付きインスタンス項の判断 $`\T{@inst-bdry-judge}\LL \Gamma, \T{inst-bdry}\LL t, k, A\LR \LR`$ は、 $`\Gamma \vdash (t :^k A) \ckw{inst}`$ と略記。
- 境界項の判断 $`\T{@bdry-judge}\LL \Gamma, A\LR`$ は、 $`\Gamma \vdash A \ckw{bdry}`$ と略記。
- 代入 $`\T{@subst}\LL \Gamma, \sigma \LR`$ は、 $`(\Gamma := \sigma)`$ と略記。
- 代入の判断 $`\T{@subst-judge}\LL \Delta, \T{@subst}\LL \Gamma, \sigma\LR \LR`$ は、 $`\Delta \vdash (\Gamma := \sigma) \ckw{subst}`$ と略記。
- 囲み記号の丸括弧は適宜省略してもよい。
上記の定義で、さまざまな構文的データの集合が定義されました。$`{\bf Decl}, {\bf Ctx}`$ などです。構文的役割りが違えば違うタグを持っているので、役割りごとの構文的データの集合は交わりません。さらに、次の定義をします。
$`\quad {\bf Term} := {\bf Bdry} \cup {\bf Inst} \:({\bf Inst} \cong \NM)\\
\quad {\bf Judge} :=\\
\qquad {\bf CtxJudge}\cup {\bf InstBdryJudge}\cup {\bf BdryJudge}\cup {\bf SubstJudge}
`$
$`{\bf Term}`$ の要素を項〈term〉、$`{\bf Judge}`$ の要素を判断〈judgement〉と呼びます。
推論規則〈inference rule〉と呼ばれる構文的データは、幾つかの判断を前提として、結論であるひとつの判断を導くルールを表すデータです。推論規則の前提には、'$`x\in \NM`$' とか '$`\mrm{dim}(A) = k - 1`$' とかの普通の論理式が入ることがあります。判断以外の論理式を副条件〈side condition〉といいます。副条件の構文は今は定義しませんが(しなくても分かる)、副条件の集合は $`{\bf Cond}`$ とします。
推論規則の定義と略記の約束は次のようになります。
- 推論規則〈inference rule〉とは、$`\T{@infer}\LL r, \LL P_1, \cdots, P_n\LR, Q\LR`$ のパターンのデータ。ここで、$`r`$ は推論規則の名前(次節参照)、$`P_i \in {\bf Judge}\cup{\bf Cond}`$ 、$`Q \in {\bf Judge}`$
- 推論規則 $`\T{@infer}\LL r, \LL P_1, \cdots, P_n\LR, Q\LR`$ は、 $`P_1\: \cdots\: P_n \hinfer^r Q`$ と略記。区切り記号は空白または改行。
推論規則
形式的体系 $`\Glob`$ の推論規則を列挙します。他の形式的体系ですが、推論規則を書いている過去記事には「最近の型理論: 具体的・構文的なコンテキスト」、「述語論理: カリー/ハワード/ランベック対応と推論・型つけ規則」があります。$`\Glob`$ の推論規則は以下のようです。
- $`\Rule{dummy-bdry}`$ ダミーな境界項 $`*`$ は無条件に正当
- $`\Rule{new-bdry}`$ 新しい境界項の構成法と正当性
- $`\Rule{trivial}`$ 自明な推論は正当な推論
- $`\Rule{ctx-thin}`$ コンテキストを水増し(thinning)しても推論の正当性は維持される
- $`\Rule{emp-ctx}`$ 空なコンテキストは無条件に正当
- $`\Rule{ctx-ext}`$ コンテキストの拡張法と正当性
- $`\Rule{emp-subst}`$ 空な代入は無条件に正当
- $`\Rule{subst-ext}`$ 代入の拡張法と正当性
コンテキスト $`\Gamma`$ に 宣言 $`(x:^k A)`$ が出現することを
$`\quad (x:^k A) \in: \Gamma`$
と書くことにします。また、コンテキスト $`\Gamma`$ に出現する宣言はコンテキスト $`\Delta`$ にも出現するとき
$`\quad \Gamma \sqsubseteq \Delta`$
と書くことにします。
以下の推論規則の記述において、項の次元関数、コンテキストの名前集合、代入の項への適用〈application〉が使われます。これは推論規則の後で述べます。$`{\bf nothing}`$ は空リスト $`\Emp`$ のことです。推論規則の名前は '$`\hinfer`$' の右肩には付けないで、見出しにします。
$`\Rule{dummy-bdry}\\
\quad \Vdash \Gamma \ckw{ctx}\\
\hinfer \Gamma \vdash * \ckw{bdry}
`$
$`\Rule{new-bdry}\\
\quad \Gamma \vdash A \ckw{bdry}\\
\quad \Gamma \vdash t :^k A \ckw{inst}\\
\quad \Gamma \vdash u :^k A \ckw{inst} \\
\hinfer \Gamma \vdash t \to u :^{k} A \ckw{bdry}
`$
$`\Rule{trivial}\\
\quad \Vdash \Gamma \ckw{ctx}\\
\quad (x :^k A) \in: \Gamma \\
\hinfer \Gamma \vdash x :^k A \ckw{inst}
`$
$`\Rule{ctx-thin}\\
\quad \Gamma \vdash u :^l B \ckw{inst}\\
\quad \Vdash \Delta \ckw{ctx}\\
\quad \Gamma \sqsubseteq \Delta \\
\hinfer \Delta \vdash u :^l B \ckw{inst}
`$
$`\Rule{emp-ctx}\\
\quad \ckw{nothing}\\
\hinfer \; \Vdash \Emp \ckw{ctx}
`$
$`\Rule{ctx-ext}\\
\quad \Gamma \vdash A \ckw{bdry} \\
\quad \mrm{dim}(A) = k - 1\\
\quad x\in \NM \land x \not\in \mrm{name}(\Gamma)\\
\hinfer \; \Vdash \Gamma \cdot (x :^k A) \ckw{ctx}
`$
$`\Rule{emp-subst}\\
\quad \Vdash \Gamma \ckw{ctx}\\
\hinfer \Gamma \vdash \Emp := \Emp \ckw{subst}
`$
$`\Rule{subst-ext}\\
\quad \Delta \vdash \Gamma := \sigma \ckw{subst}\\
\quad \Delta \vdash A \ckw{bdry} \\
\quad \mrm{dim}(A) = k - 1\\
\quad \Delta \vdash t :^k A[\Gamma := \sigma] \ckw{inst}\\
\hinfer \Delta \vdash \Gamma \cdot (x :^k A) := \sigma \cdot t \ckw{subst}
`$
キーワード $`{\bf inst}`$ が付いた判断は、インスタンス項ではなくて境界付きインスタンス項(集合 $`{\bf InstBdry}`$ の要素)に対する判断です。インスタンス項は単なる(タグが付いた)名前で所在不明なので、インスタンス項だけではあまり意味がありません。
コンテキスト $`\Gamma`$ の名前の集合は、$`\Gamma`$ 内の宣言 $`(x :^k A)`$ に出現する名前 $`x`$ 達の集合で、 $`\mrm{name}(\Gamma)`$ と書きます。$`\Gamma`$ 内に同じ名前がニ回は出現しないことは帰納法で証明できます。したがって、リストとしての $`\Gamma`$ の長さと、集合 $`\mrm{name}(\Gamma)`$ の基数は同じです。
$`\Rule{ctx-ext}`$ に出てくる副条件 $`x \not\in \mrm{name}(\Gamma)`$ は、$`x \text{ is fresh}`$ とも略記して、名前 $`x`$ は(その時点のコンテキストに対して)フレッシュ〈fresh〉だと言います。
項の次元関数 $`\mrm{dim} = \mrm{dim}_\Gamma`$ は、コンテキスト $`\Gamma`$ と相対的に次のように定義します。
- コンテキストに無関係に $`\mrm{dim}(*) = -1`$
- インスタンス項 $`t = \T{@inst}\LL x \LR`$ の名前 $`x`$ が $`(x:^k A)`$ の形の宣言として $`\Gamma`$ に出現するととき、$`\mrm{dim}(t) = k`$ 。
- 境界項 $`A = (t \to u :^k B)`$ の次元は $`\mrm{dim}(A) = k`$ 。
代入 $`(\Gamma := \sigma)`$ の項への適用〈application〉(または作用〈action〉)は次のように定義します。
- 被作用項〈オペランド〉が $`*`$ のとき: $`*[\Gamma := \sigma] := *`$
- 被作用項がインスタンス項 $`t`$ のとき:
- インスタンス項 $`t`$ の名前 $`x`$ が $`\mrm{name}(\Gamma)`$ に所属していて、その名前が $`\Gamma`$ の $`i`$ 番目に出現するとき、$`t[\Gamma := \sigma] := \sigma_i`$
- そうでないときは未定義*2
- 被作用項が境界項 $`A`$ のとき: 境界項 $`A`$ が $`(t \to u :^k B)`$ だとして、
$`A[\Gamma := \sigma] := (t[\Gamma := \sigma] \to u[\Gamma := \sigma] :^k B[\Gamma := \sigma])`$
導出の例
形式的体系 $`\Glob`$ の導出ツリーという構文的データを(次節で)説明する前に、導出ツリーの実例を挙げておきます。
次のような2次元ペースティング図を考えます。
$`\quad \xymatrix{
{\AN{a}} \ar@/^1pc/[r]^{\AN{f}} \ar@/_1pc/[r]_{\AN{g}}
\ar@{}[r]|{\AN{A}\, \Downarrow}
& {\AN{b}}
}`$
出現する名前は、変数ではなくて、$`\NM`$ の要素そのものだとします。それを強調するために、名前をサンセリフ体にしています。
2-セル $`\AN{A}`$ のプロファイルパスは次のようになります。
$`\quad \AN{A} :: \AN{f} \twoto \AN{g} : \AN{a} \to \AN{b}`$
矢印記号はシンプルな矢印だけにして、コロンの個数は左肩指数で表すとします。さらに、ダミーの(-1)次元セルも含めると、$`\AN{A}`$ のプロファイルパスは次のように書けます。
$`\quad \AN{A} :^2 \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 *`$
プロファイルパスの宣言を一種の命題と考えて、形式的体系 $`\Glob`$ における“導出”を考えます。以下のような判断の並びは、導出過程をある程度は表現していると言えるでしょう。
- $`\Vdash \Emp \ckw{ctx}`$
- $`\Emp\vdash * \ckw{bdry}`$
- $`\Vdash \LL \AN{a} :^0 * \LR \ckw{ctx}`$
- $`\LL \AN{a} :^0 * \LR \vdash * \ckw{bdry}`$
- $`\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 * \LR \ckw{ctx}`$
- $`\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash \AN{a}:^0 * \ckw{inst}`$
- $`\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash \AN{b}:^0 * \ckw{inst}`$
- $`\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash \AN{a} \to \AN{b} :^0 * \ckw{bdry}`$
- $`\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 * ,\AN{f}:^1 \AN{a} \to \AN{b} :^0 *\LR \ckw{ctx}`$
- $`\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 * , \AN{f}:^1 \AN{a} \to \AN{b} :^0 * , \AN{g}:^1 \AN{a} \to \AN{b} :^0 * \LR \ckw{ctx}`$
- $`\LL \AN{a} :^0 *, \AN{b}:^0 * , \AN{f}:^1 \AN{a} \to \AN{b} :^0 * , \AN{g}:^1 \AN{a} \to \AN{b} :^0 * \LR \vdash \AN{f}:^1 \AN{a} \to \AN{b} :^0 * \ckw{inst}`$
- $`\LL \AN{a} :^0 *, \AN{b}:^0 * , \AN{f}:^1 \AN{a} \to \AN{b} :^0 * , \AN{g}:^1 \AN{a} \to \AN{b} :^0 * \LR \vdash \AN{g}:^1 \AN{a} \to \AN{b} :^0 * \ckw{inst}`$
- $`\Vdash \\ \LL \AN{a} :^0 *, \AN{b}:^0 * , \AN{f}:^1 \AN{a} \to \AN{b} :^0 * , \AN{g}:^1 \AN{a} \to \AN{b} :^0 *, \AN{A} :^2 \AN{f} \to \AN{g}:^1 \AN{a} \to \AN{b} :^0 *\LR \\ \quad \ckw{ctx}`$
- $`\LL \AN{a} :^0 *, \AN{b}:^0 * , \AN{f}:^1 \AN{a} \to \AN{b} :^0 * , \AN{g}:^1 \AN{a} \to \AN{b} :^0 * , \AN{A} :^2 \AN{f} \to \AN{g}:^1 \AN{a} \to \AN{b} :^0 *\LR\\ \quad \vdash \AN{A} :^2 \AN{f} \to \AN{g}:^1 \AN{a} \to \AN{b} :^0 * \ckw{inst}`$
導出過程をもっと精密に記述するために、次の3段階に分けます。
- 0次元のコンテキスト $`\LL \AN{a} :^0 *, \AN{b}:^0 * \LR`$ の構成
- 1次元のコンテキスト $`\LL \AN{a} :^0 *, \AN{b}:^0 * , \AN{f}:^1 \AN{a} \to \AN{b} :^0 * , \AN{g}:^1 \AN{a} \to \AN{b} :^0 * \LR`$ の構成
- 2次元のプロファイルパス宣言 $`\AN{A} :^2 \AN{f} \to \AN{g}:^1 \AN{a} \to \AN{b} :^0 *`$ の構成
第1段階:
判断・副条件の右側に番号を振ります。推論規則の前提として使った判断・副条件を、推論規則名に続けて書きます。推論規則の結論は '$`\vinfer`$' の行の次の行です。
$`\ckw{nothing}\\
\vinfer \Rule{emp-ctx}\\
\Vdash \Emp \ckw{ctx} \num{1} \\
\vinfer \Rule{dummy-bdry} (1)\\
%
\Emp \vdash * \ckw{bdry} \num{2}\\
\mrm{dim}(*) = -1 \num{3}\\
\AN{a} \in \NM \land \AN{a} \text{ is fresh}\quad\text{--}(4)\\
\vinfer \Rule{ctx-ext} (2), (3), (4)\\
%
\Vdash \LL \AN{a} :^0 * \LR \ckw{ctx} \num{5}\\
\vinfer \Rule{dummy-bdry} (5)\\
%
\LL \AN{a} :^0 * \LR \vdash * \ckw{bdry} \num{6}\\
\mrm{dim}(*) = -1 \num{7} \\
\AN{b} \in\NM \land \AN{b} \text{ is fresh}\num{8}\\
\vinfer \Rule{ctx-ext} (6), (7), (8)\\
%
\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 * \LR \ckw{ctx} \num{9}
`$
第2段階:
$`\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 * \LR \ckw{ctx} \num{9}\\
\vinfer \Rule{dummy-bdry} (9)\\
%
\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash * \ckw{bdry} \num{10}\\
(\AN{a} :^0 *) \in: \LL \AN{a} :^0 *, \AN{b}:^0 * \LR \num{11}\\
\vinfer \Rule{trivial} (9),(11)\\
%
\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash \AN{a}:^0 * \ckw{inst} \num{12}\\
(\AN{b} :^0 *) \in: \LL \AN{a} :^0 *, \AN{b}:^0 * \LR \num{13}\\
\vinfer \Rule{trivial} (9),(13)\\
%
\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash \AN{b}:^0 * \ckw{inst} \num{14}\\
\vinfer \Rule{new-bdry}(10),(12),(14)\\
%
\LL \AN{a} :^0 *, \AN{b}:^0 * \LR \vdash \AN{a} \to \AN{b} :^0 * \ckw{bdry} \num{15}\\
\mrm{dim}(\AN{a} \to \AN{b} :^0 * ) = 0 \num{16}\\
\AN{f} \in \NM \land \AN{f} \text{ is fresh}\num{17}\\
\vinfer \Rule{ctx-ext}(15), (16), (17)\\
%
\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * \LR \ckw{ctx} \num{18}\\
\AN{g} \in \NM \land \AN{g} \text{ is fresh}\num{19}\\
\vinfer \Rule{ctx-ext}(15), (16), (19)\\
%
\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \ckw{ctx} \num{20}
`$
第3段階:
$`\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \ckw{ctx} \num{20}\\
(\AN{f} :^1 \AN{a} \to \AN{b} :^0 * ) \in: \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \num{21}\\
\vinfer \Rule{trivial} (20), (21) \\
%
\LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \vdash \AN{f} :^1 \AN{a} \to \AN{b} :^0 * \ckw{inst} \num{22}\\
(\AN{g} :^1 \AN{a} \to \AN{b} :^0 * ) \in: \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \num{23}\\
\vinfer \Rule{trivial} (20), (23) \\
%
\LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \vdash \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \ckw{inst} \num{24}\\
\vinfer \Rule{new-bdry} (15), (22), (24)\\
%
\LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \\
\quad \vdash \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 *\ckw{bdry} \num{25}\\
\quad \mrm{dim}(\AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 *) = 1 \num{26}\\
\quad \AN{A} \in \NM \land \AN{A} \text{ is fresh}\num{27}\\
\vinfer \Rule{ctx-ext} (25), (26), (27)\\
%
\Vdash \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 *, \AN{A}:^2 \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR\\
\quad \ckw{ctx} \num{28}\\
(\AN{A}:^2 \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 * )\in: \\
\quad \LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 *, \AN{A}:^2 \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR \num{29}\\
\vinfer \Rule{trivial} (28), (29)\\
\LL \AN{a} :^0 *, \AN{b}:^0 *, \AN{f} :^1 \AN{a} \to \AN{b} :^0 * , \AN{g} :^1 \AN{a} \to \AN{b} :^0 *, \AN{A}:^2 \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \LR\\
\quad \vdash \AN{A}:^2 \AN{f} \to \AN{g} :^1 \AN{a} \to \AN{b} :^0 * \ckw{inst} \num{30}
`$
以上は、テキストで書きましたが、導出過程を絵図に描けば次のようです。
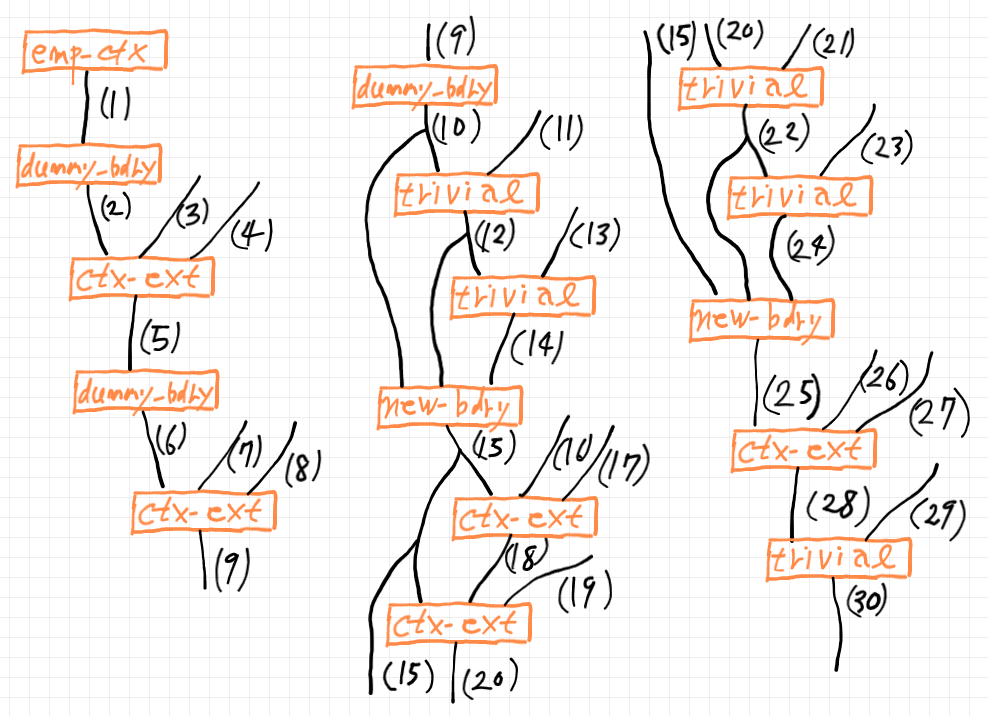
導出ツリーと導出可能性
導出過程を表す絵図は、分岐を持つので実際はツリーではありません。が、共有されている部分を複製して描くことによりツリー状の図形とみなすことができます。なので、以下、ツリーとして記述します。ただし、ルートやリーフがノードとは限らず、開いた有向辺(フラグと呼ぶ)が終端(ルートまたはリーフ)になることがあります。
終端がノードとは限らないグラフは半グラフ〈セミグラフ〉といいます(「半グラフの様々な定義」参照)。ここでは、半グラフを避けるために、ダミーのルートとダミーのリーフノードを追加して扱うことにします。例えば、前節の例の一部を切り取ったツリーにダミーのルートとダミーのリーフノードを追加すると以下のようです。
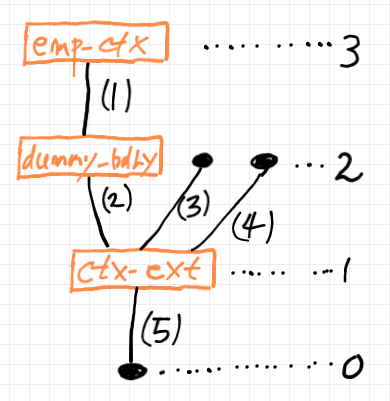
黒いドットで描いてあるノードがダミーのノードです。右側の数値は、ルートノードを高さ 0 として高さの値です。
平面(座標を入れれば $`{\bf R}^2`$)に描かれるツリーに関しては、最近の記事「指標の話: ペースティング図とバタニン・ツリー // バタニン・ツリー」で述べているので、その定義を採用します。ノード〈頂点〉達は高さで分類され、ルート以外のノードには親ノードが定まります。同じ親を持つ兄弟ノード達〈siblings〉は全順序集合になります。
さて、形式的体系 $`\Glob`$ の導出ツリー〈derivation tree〉は、上記の意味の有限平面ツリー〈finite planar tree〉ですが、次の特徴を持ちます。
- ダミーノード以外のノードには、推論規則(の名前)がラベルされる。
- 辺には、判断または副条件がラベルされる。
- 推論規則のノードに対して、入る辺のラベル達のリストと出る辺のラベルは、$`\Glob`$ の構文規則のパターンを満たしている。
子ノードを持たない推論規則ノードは $`\Rule{emp-ctx}`$ に限るので、導出ツリーのリーフノードは、$`\Rule{emp-ctx}`$ か、または副条件に対応するダミーノードです。一方、ルート(に向かう辺)のラベルは次のいずれかです。
- 境界項の判断
- 境界付きインスタンス項の判断
- コンテキストの判断
- 代入の判断
これら4種類を総称して判断と呼んでいたので、ルート(に向かう辺)には判断がラベルされます。
$`\Glob`$ の判断が、その判断をルートとする導出ツリーを持つなら(存在するなら)、判断は導出可能〈derivable〉といいます。
この節に内容に関連して、次の過去記事が参考になるかも知れません。
構文的正当性
形式的体系 $`\Glob`$ を構成する構文的なデータの集合には次があります。
- $`{\bf Decl}`$
- $`{\bf Ctx}`$
- $`{\bf Bdry}`$
- $`{\bf Inst}`$
- $`{\bf CtxJudge}`$
- $`{\bf InstBdry}`$
- $`{\bf InstBdryJudge}`$
- $`{\bf BdryJudge}`$
- $`{\bf Subst}`$
- $`{\bf SubstJudge}`$
これらの集合の部分集合として、構文的に正当な(あるいは整形式な)データの集合があります。
- $`{\bf wfDecl}`$ : 対応する“境界付きインスタンス項の判断”が導出可能なとき構文的に正当
- $`{\bf wfCtx}`$ : 対応する“コンテキストの判断”が導出可能なとき構文的に正当
- $`{\bf wfBdry}`$ : 対応する“境界項の判断”が導出可能なとき構文的に正当
- $`{\bf wfInst}`$ : インスタンス項単独ではあまり意味がないが、便宜上、すべてのインスタンス項を構文的に正当〈整形式〉としておく。
- $`{\bf wfCtxJudge}`$ : 導出可能な判断は構文的に正当
- $`{\bf wfInstBdry}`$ : 対応する“境界付きインスタンス項の判断”が導出可能なとき構文的に正当
- $`{\bf wfInstBdryJudge}`$ : 導出可能な判断は構文的に正当
- $`{\bf wfBdryJudge}`$ : 導出可能な判断は構文的に正当
- $`{\bf wfSubst}`$ : 対応する“代入の判断”が導出可能なとき構文的に正当
- $`{\bf wfSubstJudge}`$ : 導出可能な判断は構文的に正当
構文的正当性は導出可能性から定義されるので、推論規則達から生成された導出ツリー達の集合が構文的正当性を決定していると言えます。前節と同じ過去記事を参照しておきます。
構文圏
形式的体系 $`\Glob`$ の構文圏〈syntactic category〉 $`\mrm{SynCAT}(\Glob)`$ は次のように定義します。$`\cat{S} := \mrm{SynCAT}(\Glob)`$ と置きます。
- $`\cat{S}`$ の対象は、$`\Glob`$ の整形式(構文的に正当な)コンテキストとする。
- $`\cat{S}`$ の射は、$`\Glob`$ の整形式(構文的に正当な)な代入の判断とする。
つまり:
$`\quad |\cat{S}| := {\bf wfCtx}\\
\quad \mrm{Mor}(\cat{S}) := {\bf wfSubstJudge}
`$
代入の判断は $`\Delta \vdash \Gamma := \sigma`$ の形をしているので、域・余域を次のように定義します。
$`\quad \mrm{dom}(\Delta \vdash \Gamma := \sigma) := \Delta\\
\quad \mrm{cod}(\Delta \vdash \Gamma := \sigma) := \Gamma
`$
恒等射は次の形の代入の判断です。
$`\quad \LL x_1: A_1, \cdots, x_n : A_n\LR \vdash
\LL x_1: A_1, \cdots, x_n : A_n\LR := \LL x_1, \cdots, x_n \LR
`$
圏の結合〈composition〉の図式順演算子記号を '$`;`$' として記述します。また、代入の判断を一種のラムダ抽象だと思って、ラムダ記法で書くと親しみがわきます。
$`\quad \lambda\, \Delta.( \Gamma := \sigma ) \;: \Delta \to \Gamma \In \cat{S}`$
この書き方で圏の結合を定義すると:
$`\text{For }\lambda\, \Delta.( \Gamma := \sigma ) \;: \Delta \to \Gamma \In \cat{S}\\
\text{For }\lambda\, \Gamma.( \Phi := \rho ) \;: \Gamma \to \Phi \In \cat{S}\\
\quad \lambda\, \Delta.( \Gamma := \sigma ) ;\lambda\, \Gamma.( \Phi := \rho )
:= \lambda\, \Delta.( \Phi := \rho[\Gamma := \sigma] )
`$
$`\rho`$ はインスタンス項(事実上単なる名前)のリストなので、代入の適用は成分ごとに実行します。
このようにして定義した $`\cat{S} = \mrm{SynCAT}(\Glob)`$ が実際に圏の法則〈公理〉を満たすことは別途確認する必要がありますが割愛します。
圏同値
「球体集合達の圏の構文表示 1/2」において、無交差有限な球体集合の圏を定義しました。
$`\quad {\bf DisjFin}\H{{\bf G}}{\bf Set} \;\in |{\bf CAT}|`$
前節で定義した、形式的体系 $`\Glob`$ の構文圏 $`\cat{S} = \mrm{SynCAT}(\Glob)`$ は、$`{\bf DisjFin}\H{{\bf G}}{\bf Set}`$ と反変に圏同値になります。構文圏から無交差有限な球体集合の圏への対応の方針を示します。
コンテキスト $`\Gamma \in \cat{S}`$ に対して、次のような球体集合 $`X`$ を作ります。
- $`X`$ のすべてのセルの集合を $`\overline{X} := \mrm{name}(\Gamma)`$ とする。
- 名前 $`x \in \mrm{name}(\Gamma)`$ は $`(x :^k A)`$ の形でコンテキストに出現するので、$`\mrm{dim}(x) = k`$ として、セルの次元を定義する。
- 0次元ではないセル $`x`$ は、$`(x :^{k+1} t \to u : B )`$ の形でコンテキストに出現するので、$`x`$ のソース面を $`t`$ 、ターゲット面を $`u`$ と定義する。
このようにして、$`k`$ ごとに以下の構造が作れます。
$`\quad \T{s}^X_k, \T{t}^X_k : X_{k + 1} \to X_k \In {\bf FinSet}`$
全体として球体恒等式を満たすことを確認すれば、$`X`$ は球体集合となります。
コンテキスト $`\Gamma`$ に対応する球体集合が $`X`$ 、コンテキスト $`\Delta`$ に対応する球体集合が $`Y`$ とするとき、代入の判断 $`\lambda\,\Delta.(\Gamma :=\sigma)`$ が、球体集合のあいだの逆向きの写像 $`f`$ を定義します。
$`\quad f: X \to Y \In {\bf DisjFin}\H{{\bf G}}{\bf Set}`$
このことも、順番に確認していけば示せます。
結局、$`\cong`$ を圏同値だとして次が言えます。
$`\quad \mrm{SynCAT}(\Glob)^\mrm{op} \cong {\bf DisjFin}\H{{\bf G}}{\bf Set} \In {\bf CAT}\\
\quad {\bf DisjFin}\H{{\bf G}}{\bf Set} \cong {\bf Fin}\H{{\bf G}}{\bf Set}\In {\bf CAT}\\
\text{i.e.}\\
\quad \mrm{SynCAT}(\Glob)^\mrm{op} \cong {\bf Fin}\H{{\bf G}}{\bf Set}\In {\bf CAT}
`$