「指標記述のための構文」において、ホスト構文/ゲスト構文の問題(「箱を開ける鍵は箱の中」問題)に触れました。この問題の話をしようかと思ったのですが、若干の予備知識が要りますね。この記事で、コンピュータによる言語処理の常識的事項につて解説します。この記事だけ独立に読めます。
内容:
レキシングとパージング
テキスト文字列が意味を持つとして、その意味を解釈するには、テキスト文字列を単語に切り分けて、単語の並びを文にまとめて、さらに文のなかの主語、動詞、目的語などを識別する必要があります。このことは、自然言語テキストだけの話ではなくて、人工的な構文を持つテキストに関しても同様です。
これから扱う言語は自然言語ではなくて人工言語です。人工言語の構文は、明示的に約束された語彙と文法で決まります。語彙とは単語の集まり、文法は単語をどう組み合わせたら句や文が出来るかを規定した規則集です。
コンピュータによる言語処理では、単語をトークンまたは字句と呼びます。テキスト文字列を単語に切り分ける操作は、トークン化〈tokenize〉または字句解析〈lexical analysis〉と呼びます。トークン化のことをレキシング〈lexing〉と呼ぶこともあります。色々な言い方があるんです*1。
レキシング〈トークン化〉により、文字列はトークン列になります。トークン列は直線的な並びですが、この並びから文法的な構造を持ったツリーを構成する操作をパージング〈parsing〉*2と呼びます。パージングは狭義の構文解析です。広義の構文解析はレキシングとパージングを一緒にしたものです。
レキシング/パージングの実例
2*x + 14 = 0 という数式(方程式)は、人工言語によるテキスト文字列です。これをレキシング/パージングしてみましょう。
まずレキシング〈トークン化〉です。テキスト文字列をトークンに切り分けると同時に、品詞に相当するトークン型の識別も行います。結果は次のようです。
| トークン | トークン型 |
|---|---|
| "2" | 数値 |
| "*" | 掛け算記号 |
| "x" | 変数 |
| "+" | 足し算記号 |
| "14" | 数値 |
| "=" | 等号 |
| "0" | 数値 |
これで、"2", "*", "+", "14", "=", "0" というトークン列ができました。空白は読み飛ばされます。
トークン列をパージングするには、文法規則〈grammar rule | production rule〉が必要です。文法規則の記述にはBNF〈バッカス/ナウア形式 | Backus-Naur form〉記法やその変種が使われることが多いです。BNF記法については:
ここでの文法規則は次のようにしましょう。トークン型は角括弧で囲み、そうでない文法的な種別(非終端記号といいます)は丸括弧で囲むことにします。記号「::=」は、左辺が右辺のパターンで定義されることを意味します。縦棒は「または」を意味します。
(方程式) ::= (式) [等号] (式) (式) ::= (項) | (式) [足し算記号] (項) (項) ::= (因子) | (項) [掛け算記号] (因子) (因子) ::= [数値] | [変数]
この文法規則に従って先の方程式 2*x + 14 = 0 を(レキシングしてから)パージングすると、以下のようなツリー構造ができます。
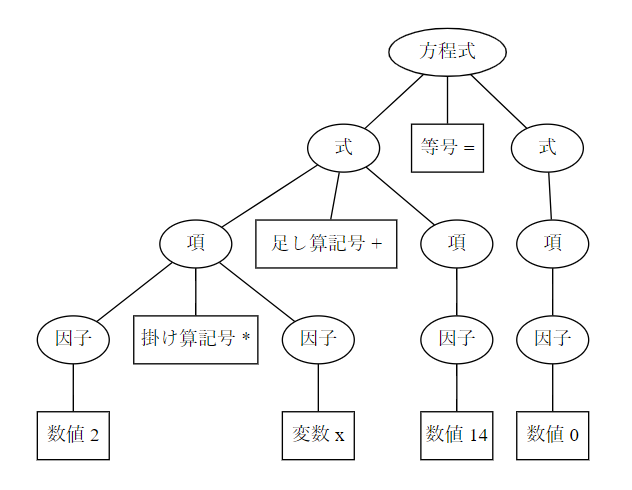
意外と複雑ですね。下側の四角い箱(トークン)を左から右にたどっていくと、もとのトークン列 "2", "*", "+", "14", "=", "0" が再現します。その他の丸いノードは文法的なまとまり(句や文に相当)を表します。丸いノードを適当に選ぶと、そのノードから下のサブツリーが部分的なまとまりを表します。
なお、先程の文法規則は、繰り返しを表すアスタリスクを使って書いたほうが便利かも知れません(以下)。
(方程式) ::= (式) [等号] (式) (式) ::= (項) ([足し算記号] (項))* (項) ::= (因子) ([掛け算記号] (因子))* (因子) ::= [数値] | [変数]
シェブロテインを使った実装
シェブロテイン〈Chevrotain〉という、パーザー構築ツールキット〈Parser Building Toolkit for JavaScript〉があります。
これは、パーザー・ジェネレーターではなくて*3、JavaScriptに埋め込まれたDLS〈Domain Specific Language〉だと謳っています。実行は高速で、なかなか使いやすいDSLになっています。
シェブロテインの解説もいつかするかも知れませんが、今日のところは、トークンの定義や文法規則をプログラミング言語(TypeScript使用)で書くと“こんな感じ”と示すだけです。雰囲気がわかれば十分なので、細かい説明はしません。
パージングをするメソッドの表示名に日本語を使ってますが、これは説明のためで、実際にはおすすめしません。メソッド名と表示名は一致させておいたほうが無難です。
import { createToken, TokenType, Lexer, IToken, CstParser, CstNode, CstElement, IRecognitionException } from 'chevrotain'; /* * トークン型の定義 */ // [数値] const NumberLiteral = createToken({ name: "数値", pattern: /0|(-?[1-9][0-9]*)/ }); // [変数] const Variable = createToken({ name: "変数", pattern: /[a-zA-Z]+/ }); // [掛け算記号] const Times = createToken({ name: "掛け算記号", pattern: /\*/ }); // [足し算記号] const Plus = createToken({ name: "足し算記号", pattern: /\+/ }); // [等号] const Equal = createToken({ name: "等号", pattern: /=/ }); // [空白] スキップ const Whitespace = createToken({ name: "空白", pattern: /\s+/, group: Lexer.SKIPPED }); /* * レクサーで使用するすべてのトークン型のリスト */ const allTokenTypes : TokenType[] = [ NumberLiteral, Variable, Times, Plus, Equal, Whitespace ]; /* * パーザークラスの定義 */ export class ArithEqParser extends CstParser { lexer: Lexer; constructor() { super(allTokenTypes); this.lexer = new Lexer(allTokenTypes); this.performSelfAnalysis(); } public parse = ( source: string, ): { errors: IRecognitionException[]; cst: CstNode; } => { this.input = this.lexer.tokenize(source).tokens; const cst = this.equation(); const errors: IRecognitionException[] = [...this.errors]; return { errors, cst }; }; /* * ここから下は文法規則〈grammar production rules〉 */ // (方程式) ::= (式) [等号] (式) equation = this.RULE("方程式", () => { this.SUBRULE1(this.expression); this.CONSUME(Equal); this.SUBRULE2(this.expression); }); // (式) ::= (項) ([足し算記号] (項))* expression = this.RULE("式", () => { this.SUBRULE(this.term); this.MANY(()=> { this.CONSUME(Plus); this.SUBRULE2(this.term); }); }); // (項) ::= (因子) ([掛け算記号] (因子))* term = this.RULE("項", () => { this.SUBRULE(this.factor); this.MANY(() => { this.CONSUME(Times); this.SUBRULE2(this.factor); }); }); //(因子) ::= [数値] | [変数] factor = this.RULE("因子", () => { this.OR([ {ALT: () => this.CONSUME(NumberLiteral)}, {ALT: () => this.CONSUME(Variable)} ]); }); }
レクサー(レキシングをするソフトウェア部分)とパーザー(パージングをするソフトウェア部分)は以上ですが、2*x + 14 = 0 がどのようにパージングされるかを確認したいなら、次のコードを付け足します。
function spaces(n: number): string { let s = ""; while (n--) { s += " "; } return s; } function isIToken(t: object): t is IToken { if (t.hasOwnProperty('image')) return true; return false; } function printCst(cst: CstElement, indent: number): void { if (isIToken(cst)) { console.log(spaces(indent) + `"${cst.image}"`); return; } console.log(spaces(indent) + `<${cst.name}> {`); let dir = cst.children; for (const key in dir) { console.log(spaces(indent + 1) + `${key}: [`); dir[key].map((x) => {printCst(x, indent + 2)}); console.log(spaces(indent + 1) + `]`); } console.log(spaces(indent) + `}`); } let text = ` 2*x + 14 = 0 `; let parser = new ArithEqParser(); let result = parser.parse(text); printCst(result.cst, 0);
実行してみると次のようになります。シェブロテインのCST〈Concrete Syntax Tree | 具象構文解析木〉は、ノードの子ノード達がリスト〈配列〉ではなくて、構文的種別〈非終端記号〉をキーとするオブジェクトになっていて、当該のキーの値がリストになる構造です。
<方程式> {
式: [
<式> {
項: [
<項> {
因子: [
<因子> {
数値: [
"2"
]
}
<因子> {
変数: [
"x"
]
}
]
掛け算記号: [
"*"
]
}
<項> {
因子: [
<因子> {
数値: [
"14"
]
}
]
}
]
足し算記号: [
"+"
]
}
<式> {
項: [
<項> {
因子: [
<因子> {
数値: [
"0"
]
}
]
}
]
}
]
等号: [
"="
]
}