同義語・多義語の問題について過去3回の記事で述べました。
同義語・多義語の問題は、正確なコミュニケーションにとっては深刻な障害となります。対策・対処としては、語彙目録を共有するのが良かろう、と思います。この記事(と引き続く記事)では、語彙目録の作成と運用について具体的に考えていきたいと思います。
内容:
関連記事:
- デジタル語彙目録:: 動機と概要(この記事)
- 指標とヒルベルト・イプシロン記号を利用しよう
- デジタル語彙目録:: 名前の管理
- 名前が指すモノ: 単射を例として
- デジタル語彙目録:: こんな感じ(中間報告)
- デジタル語彙目録:: 野生の言葉達と索引
- デジタル語彙目録:: Obsidian Publish によるWeb公開
語彙目録の用途・目的
語彙目録〈lexicon〉とは、辞書、索引、用語集のような、用語〈専門用語〉の説明を集めたものです(「同義語・多義語の問題: タグによる修飾と分類」参照)。用語の説明を与える単位が語彙エントリー〈lexical entry〉です。
インターネット上の Wikipedia や nLab は語彙目録だと言えます。各ページが語彙エントリーです。が、Wikipedia や nLab のようなものを自前で作ろう、とういことではありません。ここで考える語彙目録は、プライベートまたはローカルなものです。もっと端的に言えば、同義語・多義語の問題を解決するための手段として語彙目録を捉えています。
集団に属する人々が、言葉の意味や用法に対して強く合意していて、解釈・見解が一致しているとき、その集団をボキャブラリーに関して同調している〈completely aligned〉ということにしましょう。ボキャブラリーに関して同調している集団内のコミュニケーションなら、同義語・多義語による行き違いが発生するリスクは少ないでしょう。
が、ボキャブラリーに関して同調してない集団(二人でも集団)において、「フィールド」「クラス」「リレーション」などの言葉を無造作に使うのはとても危ない。理解の程度が違うならまだいいのですが、まったく食い違った解釈・連想がされることもあります。用語レベルで食い違っていたら、情報が正しく伝わるはずがありません。
僕は、個人あるいは小規模な集団におけるローカルルールとしての語彙目録の必要性を強く感じています。言葉の解釈の食い違いや、言葉の印象からの連想・妄想は実に侮れないもので、コミュニケーションをすっかり破綻させてしまいます。
コミュニケーションの土台・準拠枠としての語彙目録が欲しいのです。
言葉と意味
言葉と意味の関係はおおよそ次の図のようです。
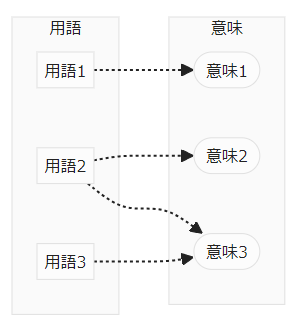
点線の矢印は、「意味する」矢印です。矢印根本の用語が、矢印先端の意味を表します。「意味とはなんぞや?」「意味するとはいかなることか?」と聞かれると返答に窮します。厳密なことはともかくとして、この絵で“気持ち”は伝わるでしょう。
用語1と意味1は一対一対応しています。用語2は多義語で、意味2と意味3のふたつの意味を持ちます。意味3から見ると、意味2と用語3は同義語です。
“意味の意味”は厳密には記述しにくいもので、あまりハッキリしてません。しかし、用語は文字列なので、デジタルデータ(Unicode文字列)としてハッキリ定義できます。ハッキリしない“意味そのもの”の代理として、語彙エントリーを考えます。語彙エントリーもデジタルデータ(例えばファイル)にすれば、デジタル的実体となります。
意味の代理に語彙エントリーが存在するとき、状況は次のようになります。用語の意味は、エントリー〈語彙エントリー〉を経由することになります。
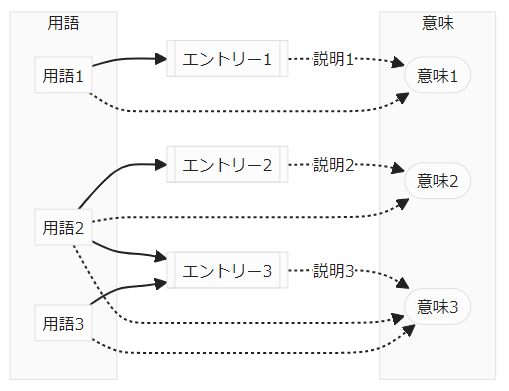
実線矢印は、デジタルの世界で物理的にハッキリと実現される関係です。点線矢印は、概念的なフンワリした関係ですが、理想化してその存在を仮定します。
実線矢印で示される関係は「用語(文字列)が、語彙エントリー(例えばファイル)に記載されている」ということなので記載関係〈mention relation〉と呼びましょう。記載関係は、デジタルなデータ構造として実現できます。記載関係を文字列とファイル(あるいはデータベース・レコード)のあいだの関係と捉えれば、フンワリした関係ではなくなります。
というわけで、「ひとつの意味にひとつの語彙エントリー」なら理想的なのですが、実際に試してみると、この方針を貫徹するのは難しいですね。例えば、「レコード」という用語の意味を、「データベース」「データ構造」の文脈で説明する語彙エントリーを考えましょう。この語彙エントリーのなかで「フィールド」の説明も一緒にしたいですよね。これを、「レコード」の語彙エントリーと「フィールド」の語彙エントリーに分けるのは難しいし、無駄なことのように感じます。
別な例として「モノイド」を説明する語彙エントリーのなかでは「モノイドの二項演算」「モノイドの単位元」などについても説明するのが自然でしょう。
こういう事情で、「ひとつの意味にひとつの語彙エントリー」は実現困難です。実際には、次のようになります。
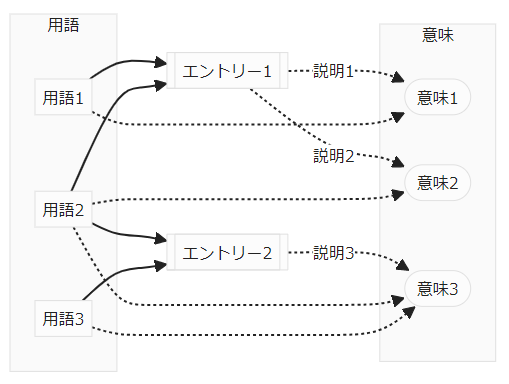
エントリー1には2つの説明が含まれます。説明1により用語1の意味が記述され、説明2により用語2の意味のうちのひとつが記述されます。エントリー2には説明がひとつです。この説明により、用語2の意味のうちの別なひとつと用語3の意味が記述されます。
多義語は複数の語彙エントリーに記載されます。文脈のなかでどの意味なのかは、語彙エントリーに付いているタグ(「同義語・多義語の問題: タグによる修飾と分類」参照)を頼りに判断します。
語彙目録は、用語に対して語彙エントリーを検索する検索システムとして機能します。検索結果を絞り込む主たる方法はタグです。
デジタル語彙目録を作る
最初の節で述べた用途・目的で、前節で述べた構造を持つ語彙目録は、デジタルデートとして実現されます。今どき、デジタルではない語彙目録のほうが考えにくいですから、あえて「デジタル」を付ける必要もありませんが、作成や共有にはソフトウェア支援が必要なことを強調したいときはデジタル語彙目録〈digital lexicon〉と呼ぶことにします。
デジタル語彙目録に関して考えるべきことは:
- どうやってデジタル語彙目録を作るか?
- どうやってデジタル語彙目録を共有するか?
「どうやって?」に答えることは、具体的な手法とツールを提示することです。「共有する」ほうは後回しにして、当面は「どうやって作るか?」にフォーカスします。
まず、語彙目録作成のためのソフトウェアですが、僕が見渡した限りでは、使えそうなソフトウェアはObsidian一択です。とはいえ、当然ながらObsidianは、デジタル語彙目録作成の専用ツールではないので、幾つかのプラグインを組み合わせてゴニョゴニョすることになります。ゴニョゴニョの結果はだいぶ不格好ですが、理想のツールは現存してないので、まー致し方ないです。
Obsidianは、たくさんの小さなファイル(Markdownファイル)を扱うのが得意です。小さいファイルをまとめて大きなファイルにしてしまうと、Obsidianは本領発揮できません。なので、ひとつの語彙エントリーをひとつのファイルにします。ファイルにタグを付けたり(タギング)、ファイルのあいだにリンクを張ったり(リンキング)するのはObsidianのウリの機能で、とても優秀です。
語彙目録の語彙エントリーは、記載された(ひとつまたは複数の)用語の説明を与えます。詳細・懇切丁寧な説明が目的ではないので、必要に応じて外部の資料を参照します。インターネット上のリソースならばURLで、出版された書籍ならばISBNなどで参照できます。いずれの場合でも、LaTeXのbibファイル/bibエントリーを経由して参照するのが良いでしょう。以下はbibエントリーの一例です*1。
@misc{CJ17-19, title = {Disintegration and Bayesian Inversion via String Diagrams}, author = {Kenta Cho, Bart Jacobs}, year = {2017 submitted}, url = {https://arxiv.org/abs/1709.00322}, archiveprefix = {arXiv}, eprint = {1709.00322} }
語彙エントリーの説明の書き方は、「簡潔にわかりやすく」がモットーですが、数学/数理科学的内容ならば、形式的記述・定義〈formal description / definition〉も考慮すべきでしょう(次節)。
半形式的語彙エントリー
語彙エントリーに、証明支援系 Coq, Lean, Agda などのコードを記述すれば、用語の定義は形式的で厳密なものになります。が、小さなファイル内に書かれたコード断片をかき集めて、機械検証可能〈machine verifiable〉なファイルに再編成するのはだいぶ手間がかかります。そもそも、語彙エントリーの記述言語を証明支援系のプログラミング言語にすることはあまり現実的ではありません(そういうプロジェクトもありますが → 1Lab)。
ここでは、機械可読性を要求しない半形式的記述について考えましょう。例えば、以下は「構造記述のための指標と名前 1/n 基本」に載せた半群の指標です。もとは色が付いてましたが、ここでは色は抜いています。集合圏で考えていることを明示する $`\text{within }\mathbf{Set}`$ を追加しています。
$`\text{signature }\mathrm{Semigroup}\: \text{within }\mathbf{Set} \:\{\\
\quad \text{sort } U\\
\quad \text{operation } m : U \times U \to U\\
\quad \text{equation } \mathrm{assoc} ::
(m \times \mathrm{id}_{U} ) ; m \Rightarrow
\alpha_{U, U, U} ; (\mathrm{id}_{U} \times m) ; m \\
\}
`$
この指標による記述は、(集合圏内の)半群について十分に正確な定義になっています。指標内の名前・記号と、用語の対応は示す必要があります。
| 指標内の名前・記号 | 用語 |
|---|---|
| $`\mathrm{Semigroup}`$ | 半群 |
| $`U`$ | 半群の台集合 |
| $`m`$ | 半群の二項演算 |
| $`\mathrm{assoc}`$ | 半群の結合律 |
右側の欄の用語達が、語彙エントリーに記載された〈be mentioned〉用語達になります。
同義語や省略の情報(例えば、「『二項演算』を単に『演算』ともいい、ときに『乗法』『乗算』ともいう」とか)も、語彙目録/語彙エントリーの構造のなかで表現します。
指標をもっと簡潔に書く書き方(例えば、Agda風構文)もあるし、自然言語に近い冗長な表現を使うこともできます。書き方はひとつに決めずに、幾つかの書き方が使えたほうが便利です。ただし、「曖昧さを減少させるために、式にフォーマット指定」で述べたように「どの書き方を使ったか」は明示すべきです。
用語とシンボル
前節の指標内に出現した $`\mathrm{Semigroup}, U`$ などの名前・記号をシンボル〈symbol〉と呼ぶことにします。「シンボル」は、語彙目録について語るための用語〈テクニカルターム〉です。国語辞書的な意味で「シンボル」という言葉を使うわけではありません。
シンボルは、形式的記述/半形式的記述のなかに出現する名前・記号で、LaTeXコードで表現されるものとします。以下は、シンボルのLaTeXコードとその表示の例です。
\mathrm{Semigroup}$`\mathrm{Semigroup}`$U$`U`$\sqsubseteq$`\sqsubseteq`$!\!\rightarrow$`!\!\rightarrow`$
自然言語由来でプレーンな文字列で表現する用語と、数式由来でLaTeXコードで表現するシンボルは区別して管理することにします。
「同義語・多義語の問題: タグによる修飾と分類」で述べたように、用語はツリー状階層構造に編成せずに、フラットなままとします。ひとつの用語が複数の語彙エントリーに記載されることがありますが、それは多義語だってことです。多義性の解決は、タグをヒントに人が判断します。
一方で、シンボルは名前空間ツリーで管理します。シンボルは、名前空間ツリーのひとつの場所に配置されるので、一意的なパス名を持ちます。フルパス名によりシンボルは一意的に識別できます。
どうしてシンボルは名前空間ツリーで管理するのかというと、シンボルは、証明支援系やプログラミング言語の識別子〈identifier〉に近い使い方をするからです。そうであるならば、多義性の解決がカッチリできるメカニズムを使ったほうがいいだろう、ということです。
用法と警告
用語の用法に関しては、語彙エントリーとは別なファイルを準備してそこに書くことになるでしょう。用法〈usage〉、つまり用語の運用ルールは、特定の集団/特定の場面に適用される、省略や同義性に関するルールです。例えば:
- 「環」は「可換環」のことだとする。
- 可換とは限らない環は明示的に「非可換環」と書く。
- 一点〈要素〉の逆像は、「逆像」ではなくて「ファイバー」と呼ぶ。
- 単に「レコード」と言ったら、「フィールドのあいだに全順序があるレコード」のことだとする。
このような追加ルールや例外ルールは、語彙エントリー内に書いてしまうのはマズイですね。
警告〈caution〉は、勘違い・誤解の原因になりそうなことへの注意です。例えば:
- 「対称群〈symmetric group〉」と「対称性の群〈symmetry group〉」は違うが、どちらも「対称群」と呼ぶかも知れない。
- 「オペラッドの圏〈category of operads〉」と「オペラディック圏〈operadic category〉」は違う。
- 一点〈要素〉の逆像〈ファイバー〉には、ベキ集合を余域とするものと、集合の宇宙〈グロタンディーク宇宙〉を余域とするものがある。
警告は、語彙エントリー内に書くのもありでしょう。複数の用語の組み合わせに関する注意事項は、特定の語彙エントリー内には書きにくいので別ファイルとなるでしょうが。
用法や警告以外にも、用語を憶える助けなるエピソードや、関連する人物の情報なども語彙エントリーとは別種のファイルとしてリンクしておけば役に立つかも知れません。
学習の方法としての語彙目録作成
Obsidianを使って試しに幾つかの語彙エントリーを作ってみたのですが、知識の整理になるので、語彙エントリーを作る行為自体が学習の方法になるかも知れないと感じました。
可能性は感じたのですが、現時点において有効な学習方法/学習ツールなのか? というと、それは疑問です。Obsidianは専用ツールではないので、有り物のプラグインを組み合わせたツギハギのツールを使うことになります。ソフトウェアの支援が受けられずに注意力と根性で頑張ることもけっこうあります。セットアップの手間や使い勝手の悪さに消耗してしまって、学習どころではない、となる可能性もあります。
ツギハギではなくて、学習用に一貫して設計された気が利いたツールが登場すれば、けっこう効果的だとは思うのですが ‥ ‥
おわりに
バベルの塔の神話によると、人類は神の怒りをかって、たくさんの別々な言語を話すようになったのだとか。
Wikipedia項目「バベルの塔」より:
神は降臨してこの塔を見「人間は言葉が同じなため、このようなことを始めた。人々の言語を乱し、通じない違う言葉を話させるようにしよう」と言った。
自然言語に限らず、用語法〈テクニカルタームの体系〉においても山のような方言があり、それぞれのコミュニティが互いに「通じない違う言葉」を話しています。標準語の制定はどうせ無理なので、「通じない違う言葉」を摺り合わせて、トラブルを防ぐ算段を講じるしかないです。
*1:https://flamingtempura.github.io/bibtex-tidy/index.html を使うときれいに整形できます。