「CatyScriptで記述するCatyシェル」では、CatyシェルをCatyScriptで書いてみました。今回は、CatyによるWeb(HTTP)のリクエスト処理をCatyScriptで記述してみます。これから説明するWebリクエスト処理は、現状のCatyに基づいてますが、一部は今後に実装予定の機能です。最後に圏論的な絵(boxes and wires diagram)がオマケとして付いてます。
内容:
- まえおき
- Webリクエスト処理の流れ
- リクエスト処理のパイプライン
- リクエストとレスポンス
- スクリプトの実行とクロージャ
- リクエストディスパッチャ
- レスポンスの確認
- 例外処理と例外マッパースクリプト
- まとめと問題点
- オマケ:絵
まえおき
shiroさんからのご質問とかもあったので、もう少しCatyの内部構造を述べてみようか、と思っていたら、Kuwataさんがrequestコマンドについて書いてくれました。
実は、現状のrequestコマンドには不満があります。不満の一端はWebアダプターが色々やり過ぎる点で、次の記事に書いています。
それと、requestコマンド自体も色々やり過ぎる点が不満です。Webアダプターは薄くして、requestコマンドをもう少し単純・単機能なコマンドに分解したいのです。このことをネタにして、Catyの内部構造(の一部)を説明しましょう*1。説明のなかで使われているCatyScript2.0の構文を知るには、「Catyスクリプトの書き方 ナニカと比較編」が手っ取り早いかも。
Webリクエスト処理の流れ
CatyのWebリクエスト処理の全体は次のようになっています。
HTTPリクエスト HTTPレスポンス
--------------->[入り口処理]->[Catyのパイプライン処理]->[出口処理]-------------->
ここで、入り口処理と出口処理はCaty本体とは別なWebアダプターの仕事です*2。入り口処理を通過すると、HTTPリクエストはXJSONデータになっており、出口処理によりXJSONデータがHTTPレスポンスに直されます。
リクエスト処理の実質的な部分はCaty本体で走るパイプラインなので、以下、このパイプラインを「リクエスト処理」と呼びます。
リクエスト処理のパイプライン
リクエスト処理は、次の3段階から構成されます。
- リクエストのディスパッチ -- リクエストパス、HTTPメソッド、クエリパラメータなどから実行すべきスクリプトを割り出す。
- スクリプトの実行 -- ディスパッチにより選択されたスクリプトを実行する。
- 実行結果の確認 -- スクリプトの実行結果が正しいレスポンスかどうかを確認する。
この一連の処理をprocess-requestと名付け、CatyScriptで書けば次のとおり。
command process-request :: WebRequest -> WebResponse {
dispatch-request | exec | confirm-response
};
dispatch-request, exec, confirm-response の3つのコマンドと関連するデータ型をこれから順に書き下して、リクエスト処理の全体像を明らかにします。また、必要な例外処理も付け加えます。
リクエストとレスポンス
HTTPリクエストとHTTPレスポンスを表現するXJSONデータ型を定義します。型定義スキーマの構文は「最近のCatyスキーマを解説します」を参照してください。型の演算子「&」の意味は論理AND(集合なら共通部分)です -- & はオブジェクト型の継承の手段に使っています*3。
/** MIMEメディアタイプ */
type mediaType = string(format = "media-type");/** 文字エンコーディングスキーム */
type encoding = string(format = "encoding");/** パス */
type path = string(format = "path");/** HTTPヘッダのフィールド値 */
type fieldValue = (number|string); // Caty内では数値を許す
/** Webメッセージ。
* リクエストとレスポンスに共通な構造。
*/
type WebMessage = {
// 本質的なメタデータはヘッダに頼らないで、
// トップレベルに持つ、ヘッダとの重複は厭わない
"contentType" : mediaType,
"encoding" : encoding?, // textのときだけ
"profile" : string?,"header" : {*: fieldValue?},
"body" : (string | binary)?,* : any?
};/** Webリクエスト。
* メッセージに、リクエストパス、HTTPメソッド、動詞
* の情報が加わる。
*/
type WebRequest = WebMessage & {
"path" : path,
"method" : ("GET"|"POST"|"PUT"|"DELETE"|"HEAD"),
"verb" : string,* : any?
};/** Webレスポンス。
* メッセージに、ステータスコードの情報が加わる。
*/
type WebResponse = WebMessage & {
"status" : integer,* : any?
};
この型定義により、process-requestコマンドの入出力が何であるかはハッキリします。念のため process-request の宣言・定義を再掲:
command process-request :: WebRequest -> WebResponse {
dispatch-request | exec | confirm-response
};
スクリプトの実行とクロージャ
順序が前後しますが、先にexecについて説明します。execは入力としてスクリプトを受け取って、その実行の結果を出力します。evalと同じですが、evalより少し精密化されています。と言うのは、入力にスクリプトの実行環境も含まれるからです。
「クロージャ」という言葉は何かと物議をかもします(「クロージャとラムダ式は同義だ、と主張してみる」を参照)が、ここでは、「プログラムのコードと変数束縛のような環境を一緒にしたデータ」という意味で使います。定義は次のようにします。@[default(...)] は、デフォルト値を指定するアノテーションです*4。
/** クロージャ
*/
type Closure = {
/** 入力 */
@[default(null)]
"input" : any?,/** 変数束縛 */
@[default({})]
"vars" : object?,/** オプションパラメータ */
@[default({})]
"opts" : object?,/** 引数パラメータ */
@[default([])]
"argv" : array?,/** 実行すべきスクリプトコード */
@[default("")]
"code" : (string | binary)?
};
execコマンドは、クロージャ(Closure)型データを入力とするとします。次のような感じです。(以下で、「パーセント記号+名前・番号」は変数参照です。)
caty:test> {
> "vars": {"greeting":"Hello"},
> "argv": ["", "World"],
> "code": "[%greeting, %1]|text:concat"
> } | exec
"HelloWorld"
caty:test>
execは、クロージャの実行結果(前もって予測できない値)を出力します。実行に例外が起きる可能性もあります。よって、execの宣言は次のようになります。
command exec :: Closure -> any throws Exception;
Exceptionは、すべてのCaty例外型のスーパータイプです。throws Exception の意味は「なんらかの例外が発生するかもしれない」です*5。
リクエストディスパッチャ
dispatch-requestコマンドは、Catyのリクエストディスパッチャの機能を表現するコマンドです。
リクエストディスパッチャは、リクエストパス、HTTPメソッド、動詞(_verbクエリパラメータの値)から実行すべきスクリプトを選び出します。そして、次のようなクロージャを作ります。
- POSTデータまたはPUTデータを入力(input)とする。POST/PUT以外では入力をnullとする。
- そのときのインタプリタの状況とヘッダーの一部から変数束縛(vars)を作る。
- クエリ文字列の解析結果をオプションパラメータ(opts)とする。
- リクエストパスから引数配列(argv)を作る(諸般の事情からargvは [リクエストパス, リクエストパス] となる)。
- 選び出したスクリプトテキストをコード(code)とする。
以上のことを行うdispatch-requestコマンドの宣言は、次のようになります。
command dispatch-request :: WebRequest -> Closure throws Exception;
レスポンスの確認
dispatch-request | exec とパイプした結果は、WebResponse型であることが期待されます。しかし、それは保証されません。型の検査のために、confirm-responseコマンドを繋ぎます。confirm-responseコマンドは次のことをします。
- 入力がWebResponse型であるかどうかをチェックする。
- WebResponse型が意味的にも妥当であることを確認する。
- 問題がないならそのまま出力に流す。
- 問題があれば例外により報告する。
単なる型チェックは、validate WebResponse としても出来ます。また、Catyの総称コマンド機能が動くようになれば、型を明示した総称コマンド pass<WebResponse> でも同じ効果が得られます。confirm-responseを使うのは、「意味的にも妥当であることを確認」したいからです。例えば、ステータスコードが3xxなのにLocationヘッダがないとかもチェックするのが望ましいでしょう。
confirm-responseコマンドの宣言は以下のとおり。
command confirm-response :: any -> WebResponse throws Exception;
例外処理と例外マッパースクリプト
dispatch-request、exec、confirm-responseの宣言を並べてみます。
command dispatch-request :: WebRequest -> Closure throws Exception;
command exec :: Closure -> any throws Exception;
command confirm-response :: any -> WebResponse throws Exception;
どれも例外を起こす可能性があります。tryで囲って、例外処理を付け加える必要があります。次の形ですね。
try {dispatch-request | exec | confirm-response} |
when {
#except => // ... 例外が起きたとき
#normal => pass
}
例外処理をカスタマイズ可能とするために、例外マッパースクリプトというスクリプトファイルをユーザーが準備します。例外マッパースクリプトのファイル名は例えば map-exceptions.caty として、内容は次のような感じです*6。
when {
UnknownError => http-error-500,
AuthenticationFailed => http-error-401,
FileNotFound => http-error-404,
// ...
}
リクエスト処理中に発生する可能性があるエラーの種別(タグ)ごとに処理を並べます。この例では、単に対応するHTTPステータスを持ったレスポンスを吐き出しているだけですが、ログを書いたりもっと複雑な処理をしてもかまいません。
例外マッパーを考慮すると、リクエスト処理は次のようになります。
try {dispatch-request | exec | confirm-response} |
when {
#except => map-exceptions.caty,
#normal => pass
}
しかし、map-exceptions.caty が例外を起こしたり、変なレスポンスを作ってしまう可能性もあるので、process-requestコマンドの定義は次のようにしましょう。
command process-request :: WebRequest -> WebResponse {
try {dispatch-request | exec | confirm-response} |
when {
#except => try {map-exceptions.caty | confirm-response} |
when {
#except => http-error-500,
#normal => pass
},
#normal => pass
}
};
まとめと問題点
いま定義したprocess-requestコマンドの定義は簡単なスクリプトですが、Catyのリクエスト処理をそのまま表現しています。実際のHTTPを使うことなく、XJSONパイプラインだけでWeb処理をシミュレートできます。重要なことは、process-requestの構成要素である dispatch-request、exec、confirm-response, map-exceptions.caty が本物の処理を起動することです。つまり、実際のHTTP処理とまったく同じプログラムが走るので、本物のWebで起きたことがそのまま再現できます。
このことは、テスト、デバッグ、実験、トラブルシューティングなどにおいて非常に有効です。パイプラインの各段階で流れるデータを目視で見るだけでも相当な情報が得られることは、今までの経験からも分かっています。でも、ひとつのコマンドの機能が複雑でブラックボックスになっていると、このメリットが失われます。仕様がハッキリした単機能のコマンドを繋いだパイプラインなら、パイプラインの任意の位置をダンプする*7ことでたいていの事が分かってしまいます。これがまさにパイプ・アンド・フィルターのご利益です。
ところで今までの話では、クッキーやセッションのことが入ってません。リクエスト処理を超えて維持される状態という概念があんまりキレイに書けないのです。リクエストのディスパッチにログイン状態が関わったりする可能性を考えると、dispatch-requestに入る前に、セッション状態のセットアップをするのが良さそうです。なんとかうまく整理したいのですが ……
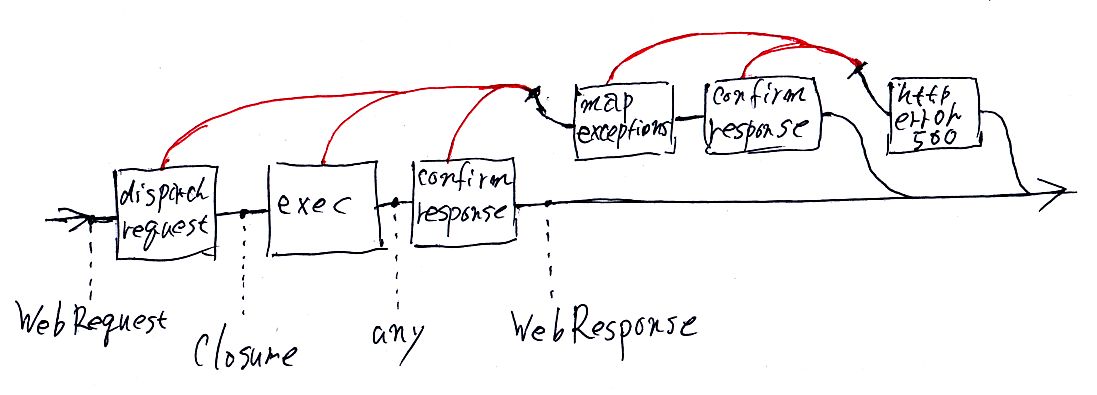
オマケ:絵
process-requestを圏論的フローチャートで表現すると下の図のようになります。
- コマンドは箱で表している。
- 黒い線は正常データの流れ、赤い線は例外データの流れ。
- 線(ワイヤー)にデータ型が注釈として記入されている。
- 線の色が赤から黒に変わるところは例外が捕捉された所。
例外の圏論的・絵算的な扱いは次を参照してください。
*1:IOとかトランザクションはモナドのクライスリ構成を拡張した両クライスリ構成(di-Kleisli construction)でモデル化するんですけど、この話は今日はしません。
*2:現在の実装では、WSGIコールバック、ミドルウェアとして実現されます。
*3:& 以外に ++ という型演算があって、これも継承に使えます。& と ++ の違いにはヤヤコシイ背景があるので割愛。
*4:XJSONのタグとアノテーションが似てるので、混同しないように注意してください。
*5:実はなにも書かなくても、throws Exception の意味になります。「例外が起きない」ことを保証するのは困難なので、起きるのを覚悟するのがデフォルトです。
*6:適切な場所に置いたスクリプトファイルは、ファイル名をコマンド名として呼び出すことができます。
*7:foo | bar の間を流れるデータが見たいなら、foo | dump | bar とします。こうしても本質的動作は変わりません。