R言語でとあるシミュレーションをしてみて、どうも納得できないことがありました。理屈では当たり前な事なんですが、どう理解すべきか分からないのです。で、「なんだこれは?」という気分
次の問題を考えます。
- 正方形内にランダムに描かれた2本の線分が交わる確率を求めよ。
これは曖昧な確率問題ですが、線分ペアを構成する4点のどの座標もすべて一様分布だとします。
まずn本の線分を一様乱数で生成して、可能なペアをすべて調べることにします。約50万ペアを調査して、交わったペアの割合は 0.2231652 でした。だいたい2割強が交わると考えることができます。
次の図は、100本の線分を生成して、そこから可能なすべてのペアの交点を求めて、それらを描いたものです。線分のペアは (100*99)/2 = 4950 組できます。交点は970個です。
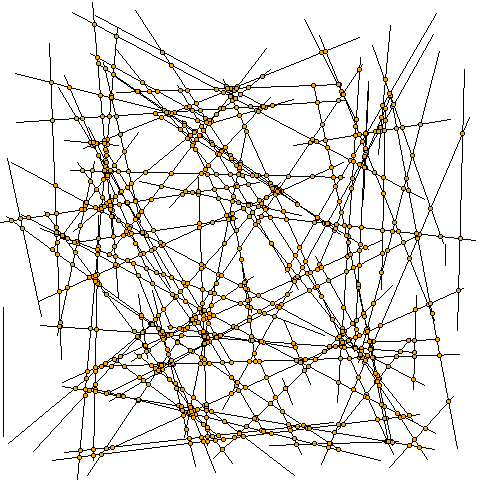
交点だけ描いてみると、次のよう。

この図から、点が直線状に並ぶことが多いことは視覚的に読み取れます。これらの点の作り方からして、それは当たり前のことです。ですが、もとの問題設定からは「点が直線に並ぶことが多い」なんて(傾向としての)法則性が出るはずはありません。
そこで、ランダムに生成した線分たちから総当りでペアで作るのではなくて、生成順で隣り合うペアだけを使うことにします。この方法では、n本の線分からn/2組のペアしか作らないので効率は悪いです。
もとの方法で100本の線分で済むところが、同じペア数確保にはほぼ二乗の一万本くらいの線分が必要です。実際に後者の方法で、一万本の線分を生成して5千ペアの交点を求めると(1173個だった)次の図です。
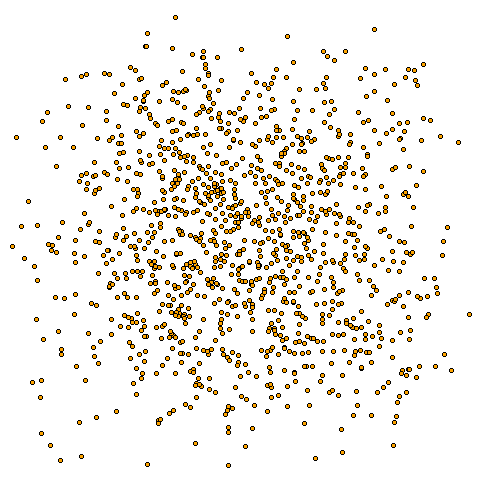
もちろん、「点が直線に並ぶことが多い」なんて傾向はありません。
2つの異なったサンプリングで異なった配置パターンが生じる -- これは起こるべくして起こった現象で、別に変なことはないのですが、最初に観測できた「点が直線に並ぶことが多い」という傾向性が気になります。
これは、調査や実験、データ処理の手順によって、その過程に由来する(傾向としての)法則性が現れる、ということです。もっと現実的な事例で、こういうことって起きるのでしょうか? 起きるとしたら何か不気味だな―、と感じました。